Web Scraping with Python: All You Need to Get Started
An introductory guide to Python web scraping with a step-by-step tutorial.
Python is the probably the most popular language for machine learning and data analysis. But it’s also a great choice for web data extraction. Adding this skill to your portfolio makes a lot of sense if you’re working with data, and it can also bring profitable opportunities.
This guide will give you all you need to start web scraping with Python. It explains why you should invest your time into Python, introduces the libraries and websites for practicing web scraping. You’ll also find a step-by-step tutorial for building a web scraper that you can replicate on your own computer. Let’s begin!
What Is Web Scraping in Python?
Web scraping refers to the process of downloading data off web pages and structuring it for further analysis. You can scrape by hand; but it’s much faster to write an automated script to do it for you.
With this approach, you don’t exactly download a web page as people see it. Rather, you extract its underlying HTML skeleton and work from there. If you’re not sure what that is, try clicking the right mouse button on this page and selecting Inspect. You should now see it as web scraper does:

Where does Python come in? Python provides the libraries and frameworks you need to successfully locate, download, and structure data from the web – in other words, scrape it.
Why Choose Python for Web Scraping
If you don’t have much programming experience – or know another programming language – you may wonder if it’s worth learning Python over the alternatives. Here are a few reasons why you should consider it:
- Simple language. Python’s syntax is relatively human-readable and easy to understand at a glance. What’s more, you don’t need to compile code, which makes it simple to debug and experiment.
- Great tools for web scraping. Python has some of the staple libraries for data collection, such as Requests with over 200 million monthly downloads.
- Strong community. You won’t have issues getting help or finding solutions on platforms like Stack Overflow.
- Popular choice for data analysis. Python ties in beautifully with the broader ecosystem of data analysis (Pandas, Matplotlib) and machine learning (Tensorflow, PyTorch).
Getting Started with Python Web Scraping
So, you decided to start scraping with Python. But where should you begin? Firstly, it’s important to think about what functionality your scraper should have.
Think about the target website. Is it static and created using only text and images, or does it have dynamic elements, such as pop-ups, real-time content updates (like, a weather forecast)? Are you going to scrape a few pages for your personal project, or is it going to be a large-scale business operation that happens often? Your answers will define what added functionality you’ll need for your Python scraper – what libraries you’ll need to use to achieve your goal.
Popular Python Libraries for Web Scraping
There are dozens of various Python libraries to handle tasks like parsing, output, browser automation, and more. A combination of them can create powerful web scrapers capable of extracting data even from very protected sites.
To build a web scraper with Python, you’ll need libraries to handle HTTP requests, to automate headless browsers, to parse data, and save your extracted information.
Here are some popular Python scraping libraries:
| Request handling | Data parsing | Browser automation |
– Requests | – Beautiful Soup | – Selenium |
The libraries tend to differ in their ease of use, syntax, efficiency, and functionality. If you’re a beginner, start with easy-to-learn libraries like Requests, Beautiful Soup, and Selenium when building your scraper.
Sending HTTP Requests with Python
In order to scrape data from HTML (static) websites, you need to send HTTP requests to download target pages. There are several ways to do that, but the most beginner friendly is by using the Requests library.
Requests
If this is your first web scraping project, I strongly suggest starting with HTTP client Requests. It’s an HTTP client that lets you download pages. The basic configuration only requires a few lines of code, and you can customize the request greatly, adding headers, cookies, and other parameters as you move on to more complex targets.
To start using Requests, you need to install it by running the following command: pip install requests. Then, create a new file and start setting up your scraper.
Here’s how you can send GET and POST requests, and Headers:
- Sending GET request
import requests
# Send a GET request to a URL
response = requests.get('https://example.com')
# Check if the request was successful (status code 200)
if response.status_code == 200:
# Print the response content
print(response.text)
else:
print('Error:', response.status_code)
- Sending POST request
import requests
# Data to be sent with the POST request
data = {'key': 'value'}
# Send a POST request to a URL with the data
response = requests.post('https://example.com', data=data)
# Check if the request was successful (status code 200)
if response.status_code == 200:
# Print the response content
print(response.text)
else:
print('Error:', response.status_code)
- Sending Headers
import requests
# Define custom headers
headers = {'User-Agent': 'MyCustomUserAgent'}
# Send a GET request with custom headers
response = requests.get('https://example.com', headers=headers)
# Check if the request was successful (status code 200)
if response.status_code == 200:
# Print the response content
print(response.text)
else:
print('Error:', response.status_code)
Python’s Requests isn’t the only HTTP client used for web scraping. There are other alternatives you can try out especially if you’re looking for better performance or asynchronous capabilities.
We compiled a list of the best Python HTTP clients for you to try.
Sending Python Asynchronous Requests with aiohttp
Requests is generally simple to grasp, but unfortunately, it can only handle synchronous requests. This means that your scraper has to wait for one task to finish before starting another. If you’re planning to do a lot of scraping, you’ll reach the scale where synchronous tools like Requests start taking too long.
Asynchronous web scraping is a technique used to send multiple requests without waiting for a response. Python’s aiohttp library is designed for this purpose.
The tool is built on top of asyncio, Python’s built-in asynchronous I/O (input/output) framework. It uses async/await syntax to manage multiple requests without blocking the main program’s execution.
If you need to set up a custom API or endpoint for your web scraper, aiohttp allows you to build web applications and APIs for managing asynchronous connections.
Here’s an example of web scraping with aiohttp:
import aiohttp
import asyncio
async def fetch_data(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
return await response.text()
async def main():
urls = [
'https://example.com/1',
'https://example.com/2',
'https://example.com/3',
# Add more URLs as needed
]
tasks = [fetch_data(url) for url in urls]
results = await asyncio.gather(*tasks)
for result in results:
print(result)
if __name__ == "__main__":
asyncio.run(main())
We’ve prepared an extensive tutorial with a real-life example if you want to practice sending asynchronous requests. You’ll learn to build a script that goes through multiple pages and scrapes the necessary information.
A tutorial on using aiohttp for sending asynchronous requests and web scraping multiple pages in parallel.
Data Parsing with Python
After you download data from your target website, there’s still little use of it – it’s hard to read and understand because there’s no structure. To get valuable insights from your scraped data, you’ll need to parse it.
Parsing is the process of cleaning and structuring data according to given parameters, and extracting the relevant information out of it. Surely, you can do that by hand, but that’s going to require a lot of resources. Instead of working through vast volumes of data manually, you can employ Python’s parsing libraries.
Python has various libraries for handling HTML, such as BeautifulSoup and lxml. These libraries allow you to navigate through HTML documents and extract target data. However, they can’t function as standalone tools, so you’ll also need to use an HTTP client to build a scraper.
Beautiful Soup
Beautiful Soup is a data parsing library that extracts data from the HTML code you’ve downloaded and transforms it into a structured format. Its syntax is simple to grasp, while the tool itself is powerful, well-documented, and lenient for beginners.
The library is very powerful. It comes with three in-built parsers – lxml, html.parser, HTML5lib – so you can use each to your advantage. It’s also light on resources, which makes it faster than other tools. Additionally, Beautiful Soup is one of a few libraries that can handle broken pages.
To start using Beautiful Soup you need to install it by running the following command: pip install beautifulsoup
Here’s an example of how to scrape with Beautiful Soup:
from bs4 import BeautifulSoup
html_data = """
<html>
<body>
<h1>Welcome to my website</h1>
<p>This is a paragraph.</p>
<a href="https://example.com">Link</a>
</body>
</html>
"""
soup = BeautifulSoup(html_data, 'html.parser')
print("Title:", soup.h1.text)
print("Paragraph:", soup.p.text)
print("Link URL:", soup.a['href'])
To learn more about web scraping Beautiful Soup, you can go straight to our step-by-step tutorial. You’ll find out how to build a simple scraper with a real-life example. The guide will also teach you how to extract the data from a single static page and add it to a CSV file for further analysis.
A step-by-step guide to web scraping with Beautiful Soup.
lxml
lxml is a powerful parsing library. The tool wraps two C libraries – libxml2 and libxalt – making lxml extensible. It includes their features like speed, and the simplicity of a native Python API.
The key benefit of lxml is that it doesn’t use a lot of memory, so you can parse large amounts of data fast. The library also supports three schema languages and can fully implement XPath, which is used to identify elements in XML documents.
Here’s an example of parsing with lxml:
from lxml import etree
html_data = """
<html>
<body>
<h1>Text</h1>
<p>This is a paragraph.</p>
<a href="https://example.com">Link</a>
</body>
</html>
"""
# Parse the HTML
root = etree.HTML(html_data)
# Extract information
title = root.find('.//h1').text
paragraph = root.find('.//p').text
link_url = root.find('.//a').get('href')
# Print the results
print("Title:", title)
print("Paragraph:", paragraph)
print("Link URL:", link_url)
To learn more about web scraping static pages, check out our tutorial with lxml and Requests. You’ll learn how to fetch HTML data, parse it, add a browser fingerprint, and extract data from a popular movie platform, IMDb.
A step-by-step guide to web scraping with Beautiful Soup.
The Difference between Beautiful Soup and xlml
So, why would you choose lxml over Beautiful Soup or vice versa? There are several key differences that can define which library is better for your use case.
Firstly, lxml can be harder to understand for beginners. While it’s not very complicated, it requires a deeper understanding of HTML tree structures, the syntax is more complex, and it’s less forgiving when it comes to broken HTML – Beautiful Soup handles it much better.
Secondly, it’s important to consider speed. lxml is faster and it uses less resources than Beautiful Soup, which is more well-suited for smaller-scale parsing projects. Beautiful Soup is powerful and quick, but due to extra data processing, it takes slightly longer to parse. Additionally, Beautiful Soup might struggle with repeated parsing tasks.
Finally, because of native XPath support, lxml is a better choice when handling XML documents. XPath helps locate elements and handle advanced queries more efficiently. That said, if you’re planning to work with HTML documents, Beautiful Soup might be better.

Building a Python Headless Browser with Selenium
Headless browsers become necessary when websites dynamically generate content through client-side scripting languages like JavaScript. Unlike static web pages, where the HTML content can be retrieved directly, dynamic web pages require rendering it first.
Selenium is one of the oldest tools to control headless browsers programmatically. Although its primary use is browser automation, Selenium remains a popular choice for web scraping JavaScript-based websites. It can control most popular web browsers and supports a variety of programming languages.
The library also includes packages to hide your digital fingerprint. Properly configured, it can automate logins or pass reCAPTCHAs, which are often a major roadblock for scraping popular websites.
Here’s an example of web scraping with Selenium:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# Set up Selenium WebDriver (make sure to download the appropriate driver for your browser)
driver = webdriver.Chrome('/path/to/chromedriver')
# Navigate to the webpage
driver.get('https://example.com')
try:
# Wait for the element to be loaded (for demonstration purposes, let's wait for the page title)
WebDriverWait(driver, 10).until(EC.title_contains("Example"))
# Once loaded, find the element(s) you want to scrape
elements = driver.find_elements(By.CSS_SELECTOR, 'p') # Example: find all <p> elements
# Extract data from the elements
for element in elements:
print(element.text)
finally:
# Close the WebDriver session
driver.quit()
If you want to learn more about web scraping with Selenium, we’ve prepared a guide for beginners. In this tutorial, you’ll learn how to deal with JavaScript-generated content, scrape multiple pages, handle delayed rendering, and write the results into a CSV file.
A step-by-step guide to web scraping with Selenium.
Selenium is a good library to start with, thanks to its prevalence, but it has some drawbacks like speed and difficulty setting up. If this is a dealbreaker for you, Python has other frameworks that can handle JavaScript-based websites.
Which one is better for web scraping?
Which tool better fits your project needs?
Other Python Web Scraping Libraries
There’s no shortage of Python web scraping libraries. The tool you choose depends on your project parameters, including the type of the target website (static or dynamic), the amount of data you want to scrape, and other aspects.
Get acquainted with the main Python web scraping libraries and find the best fit for your scraping project.
Another way to go about web scraping with Python is by using the cURL command-line tool. It offers several advantages over Python libraries, such as HTTP client Requests. For example, it’s very fast and you can send many requests over multiple connections.
This tutorial will show you the basics to use cURL with Python for gathering data.
Social Media Web Scraping with Python
Web scraping social media isn’t easy. Social platforms are probably the most strict about automated data collection and often look for ways to shut down web scraping companies. And while gathering publicly available information is legal, it’s not without roadblocks.
Many businesses and individual marketers use social media scraping to perform sentiment analysis, analyze market trends, monitor online branding, or find influencers.
If you want to try your skills in scraping social media, we have prepared Python guides covering the most popular platforms. Remember that all the scrapers are built for publicly available data. Also, social media platforms often make updates that can impact your scraper, so you might need to make some adjustments.
A step-by-step tutorial on how to scrape Reddit data using Python.
A step-by-step example of how to scrape Facebook using Python.
A step-by-step guide on how to scrape Instagram using Python.
Python Tips for Web Scraping
Devise a Web Scraping Project
If you have no business use case in mind, it can be hard to find worthwhile ideas. I recommend practicing with dummy websites. They are specially designed for being scraped, so you’ll be able to try out various techniques in a safe environment. You can find several such websites in our list of websites to practise your web scraping skills.
If you’d rather scrape real targets, it’s a good idea to begin with something simple. Popular websites like Google and Amazon offer valuable information, but you’ll encounter serious web scraping challenges like CAPTCHAs as soon as you start to scale. They may be hard to tackle without experience.
In any case, there are guidelines you should follow to avoid trouble. Try not to overload the server. And be very cautious about scraping data behind a login – it’s gotten multiple companies sued. You can find more pieces of advice in our article on web scraping best practices.
At the end, your project should have at least these basic parameters: a target website, the list of URLs you want to scrape from it, and the data points you’re interested in. If you’re short on ideas on what to scrape, we prepared a list of practical Python projects for you to try.
Ideas for beginners and advanced users.
Use Proxies
As you increase your project’s scope, you should look into proxies. They offer the easiest way to avoid blocks by giving you more IP addresses. At first, you may consider a free proxy list (because it’s free!), but I recommend investing into paid rotating proxies.
A proxy server routes traffic through itself, changing your real location and providing you with a different IP address in the meantime. This is especially important when you need to mask your identity when performing automated actions.
If you plan to scrape serious targets like Amazon, you should go with residential proxies. You’ll get a pool of IP addresses that come from real devices on Wi-Fi that are very hard to detect.
For unprotected websites, you can save money by choosing datacenter proxies. They’re much faster than their residential counterparts but relatively easy to detect.
Setting proxies with your scraper isn’t that difficult, especially when most proxy service providers include instructions on how to do so with the most popular languages and tools.
This is a step-by-step guide on how to set up and authenticate a proxy with Selenium using Python.
Building Your First Python Web Scraper
Now that you’re familiar with multiple Python libraries and some syntax, let’s build a simple Python scraper together.
Quick Python Web Scraping Tutorial

There are 1,000 books in total, with 20 books per page. Copying all 50 pages by hand would be madness, so we’ll build a simple web scraper to do it for us. It’ll collect the title, price, rating, and availability of your competitor’s books and write this information into a CSV file.
Prerequisites
- Python 3, if it’s not already on your computer, and Pip to install the necessary libraries.
- BeautifulSoup. You can add it by running
pip install beautifulsoup4in your operating system’s terminal. - Requests. You can add it by running
pip install requests.
Importing the Libraries
The first thing we’ll need to do is to import Requests and Beautiful Soup:
from bs4 import BeautifulSoup
import requests
We’ll need one more library to add the scraped data to a CSV file:
import CSV
Downloading the Page
Now, it’s time to download the page. The Requests library makes it easy – we just need to write two lines of code:
url = "http://books.toscrape.com/"
r = requests.get(url)
Extracting the Relevant Data Points
Now, it’s time to extract the data we need with Beautiful Soup. We’ll first create a Beautiful Soup object for the page we scraped:
soup = BeautifulSoup(r.content , "html.parser")
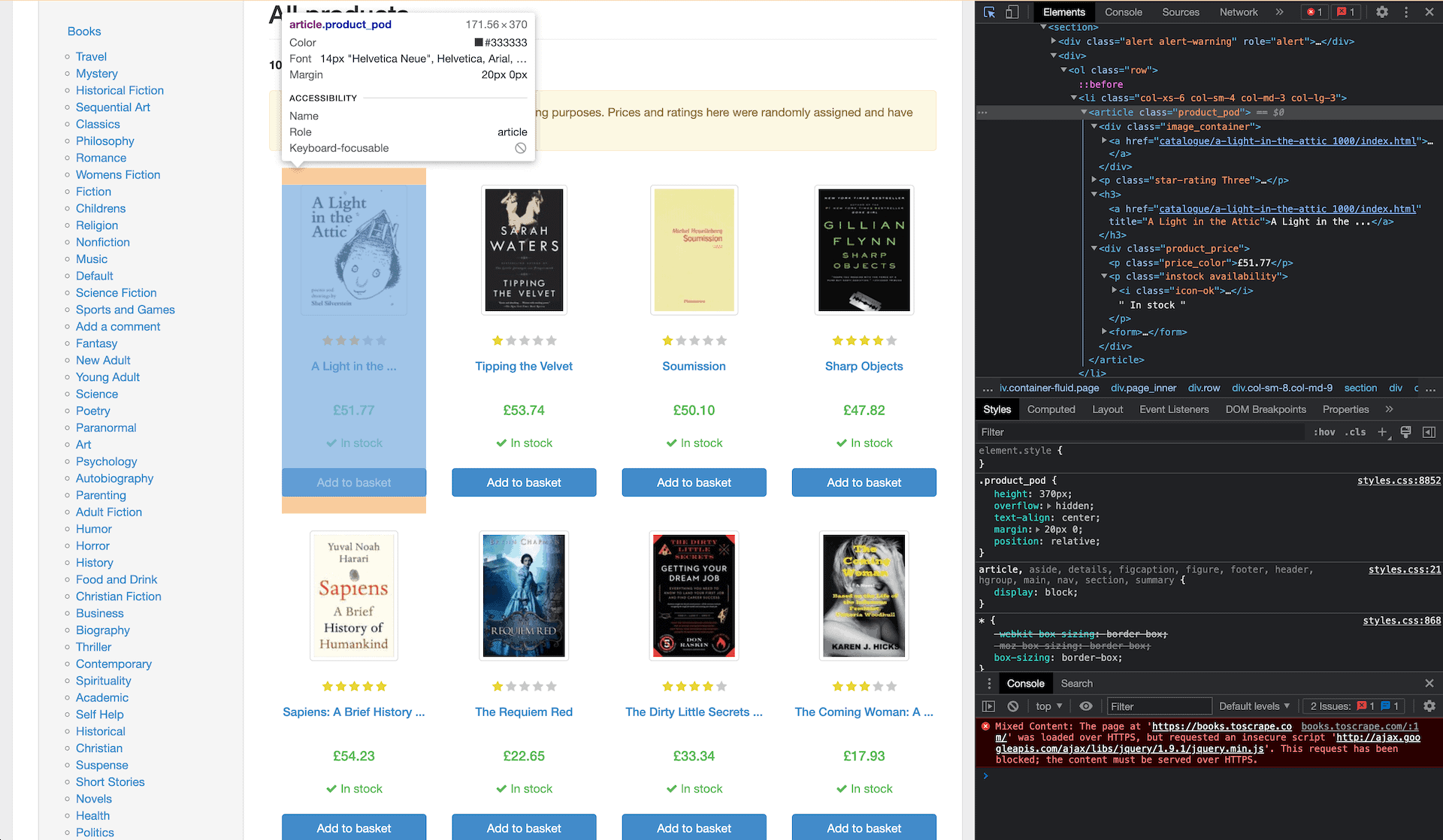
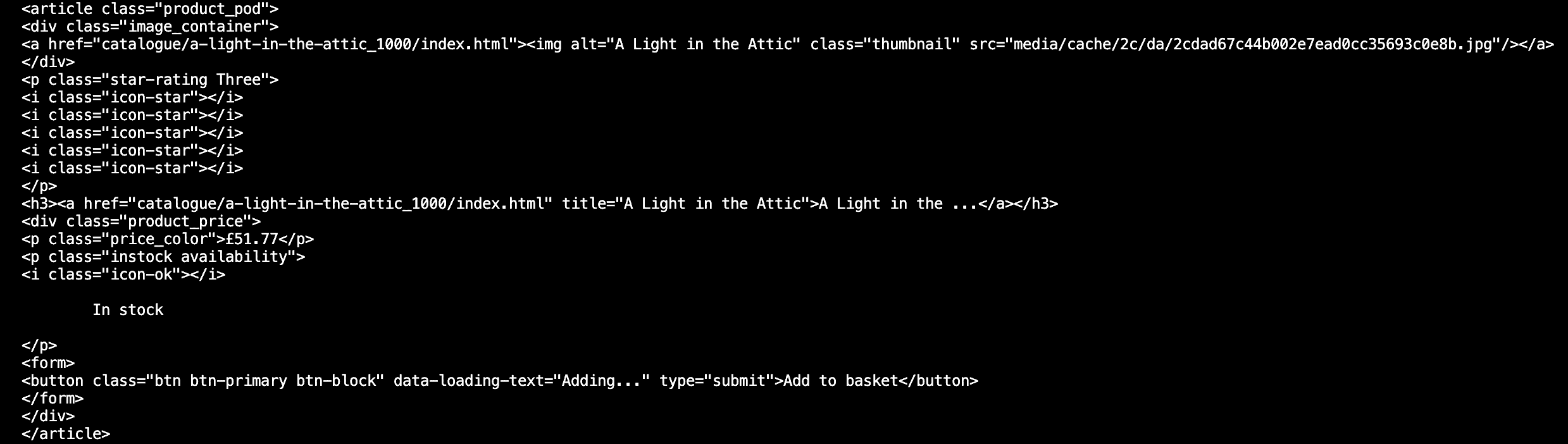
We could try extracting the whole class:
element = soup.find_all(class_="product_pod") print(element)

product_pod:
for element in soup.find_all(class_='product_pod'):
Now, let’s extract the page title. It’s nested in H3, under the <a> tag. We can simply use H3 and strip away unnecessary data (such as the URL) by specifying that we want a string:
book_title = element.h3.string
The book price is under a class called price_color. We’ll extract it without the pound symbol:
book_price = element.find(class_='price_color').string.replace('£','')
The book ratings are under the p tag. They’re more problematic to get because the rating is in the name itself, and the name includes two words (when we only need one!). It’s possible to solve it by extracting the class as a list:
book_rating = element.p['class'][1]
Finally, there’s the stock availability. It’s under a class called instock. We’ll extract the text and strip away unnecessary elements (mostly blank spaces):
#book_stock = element.find(class_="instock").get_text().strip()
Here’s the full loop:
for element in soup.find_all(class_='product_pod'):
book_title = element.h3.string
#getting the price and ridding ourselves of the pound sign
book_price = element.find(class_='price_color').string.replace('£','')
#getting the rating
#finding element class but it has two: star-rating and 'num'
#e.g. 'One' so we're only getting the second one
book_rating = element.p['class'][1]
#finding availability
book_stock = element.find(class_="instock").get_text().strip()
#we can also use:
#book_stock = element.select_one(".instock").get_text().strip()
#print out to double check
print(book_title)
print(book_url)
print(book_price)
print(book_rating)
print(book_stock)
[1] from the book_rating object. Or, delete .strip and see what happens. Beautiful Soup has many features, so there’s rarely just one proper way to extract content. Make Beautiful Soup’s documentation your friend. Exporting the Output to CSV
At this point, our script returns all the data points we wanted, but they’re not very easy to work with. Let’s export the ouput to a CSV file.
First, we’ll create an empty list object:
books = []
Then, we’ll append our data points to the list:
books.append({
'title': book_title,
'price': book_price,
'rating': book_rating,
'stock': book_stock,
'url': book_url
}
)
Finally, we’ll write the data to a CSV file:
proxies = {
'http': 'http://user:password@host:PORT',
'https': 'http://user:password@host:PORT',
}
response = requests.get('URL', proxies = proxies)
Finally, we’ll write the data to a CSV file:
with open("books_output.csv", "a") as f:
for book in books:
f.write(f"{book['title']},{book['price']},{book['rating']},{book['stock']},{book['url']}\n")

Here’s the complete script:
from bs4 import BeautifulSoup import requests import CSV url = "http://books.toscrape.com/"
r = requests.get(url) soup = BeautifulSoup(r.content , "html.parser") #books will be a list of dicts
books = []
for element in soup.find_all(class_='product_pod'):
book_title = element.h3.string
#getting the price and ridding ourselves of the pound sign
book_price = element.find(class_='price_color').string.replace('£','')
#getting the rating
#finding element class but it has two: star-rating and 'num'
#e.g. 'One' so we're only getting the second one
book_rating = element.p['class'][1]
#finding availability
book_stock = element.find(class_="instock").get_text().strip()
#we can also use:
#book_stock = element.select_one(".instock").get_text().strip()
books.append({
'title': book_title,
'price': book_price,
'rating': book_rating,
'stock': book_stock,
'url': book_url
}
)
#write it to a csv file with open("books_output.csv", "a") as f:
#not writing in a header row in this case
#if using "a" then you can open a file if it exists and append to it
#can also use "w", then it would overwrite a file if it exists
for book in books:
f.write(f"{book['title']},{book['price']},{book['rating']},{book['stock']},{book['url']}\n")
Next Steps
Wait, that’s only one page. Weren’t we supposed to scrape all 50?
That’s right. But at this point, you should start getting the hang of it. So, why not try scraping the other pages yourself? You can use the following tutorial for guidance:
A step-by-step tutorial showing how to get the URLs of multiple pages and scrape them.
It would also be useful to get the information of individual books. Why not try scraping them, as well? It’ll require extracting data from a table; here’s another tutorial to help you. You can find the full list of guides in our knowledge base.
A step-by-step guide showing how to scrape data from a table.

{kind=link}
{kind=link}
{kind=link}