ChatGPT for Web Scraping: A Step-by-Step Guide
Since its release in 2022, ChatGPT immediately became a popular choice for any query. The chatbot can help you to brainstorm ideas, write and edit text or code, and much more. So, it only makes sense to use ChatGPT for web scraping, too.

Search engines like Google are a huge help if you are looking for information, but it can take ages to find the right answer. ChatGPT, on the other hand, simplifies this process. It’s trained on large amounts of data, and it can summarize, provide understandable answers to complex questions, and respond to follow-up questions, which makes it great for many tasks, web scraping included.
While not perfect, ChatGPT can write simple code, as well as explain the logic behind it. It’s an excellent supporting tool for beginners trying to learn or seasoned scraping enthusiasts looking to improve and test their skills. So, let’s learn all the basics about web scraping with ChatGPT and try to build a simple web scraper.
What Is ChatGPT Web Scraping
ChatGPT web scraping is the process of automatically gathering data from websites using a code that’s written with ChatGPT. But if ChatGPT is a chatbot, what exactly does it do in this equation? Basically, you can ask ChatGPT to build you a scraper for a specific website you want to get data from. All you need to do is give instructions, collect certain data points for ChatGPT to use, and run the code.
How ChatGPT Can be Used for Web Scraping Tasks
ChatGPT itself isn’t a scraper and it can’t scrape websites directly, but it can help you write a simple scraper (or improve an old one) based on the instructions you give. However, while you don’t need a lot of knowledge about web scraping or writing code yourself, knowing how to create a good prompt is useful.

Scraping with ChatGPT: A Step-by-Step Guide
Let’s see how we can use ChatGPT for web scraping. In this step-by-step guide, we’ll use a website that loves to be scraped – https://books.toscrape.com/.

This website is a sandbox environment specifically designed to practice your skills and test scrapers. It’s a safe place to do different scraping experiments without worrying about violating Terms of Service or robots.txt file. There are other sandbox websites similar to books.toscrape.com, but for the sake of this experiment, let’s use this one.
We prepared a list of sandboxes just for you.
Let’s create a Python scraper that extracts book titles and their prices from the page. We’ll be using Python because it’s a beginner-friendly programming language with a simple syntax that excels in tasks like web scraping. We’ll also use two Python libraries to assist, namely, Requests for handling HTML requests, and Beautiful Soup for parsing (cleaning) extracted data.
We’ll later save extracted data in CSV – a simple text format which will allow you to open, edit, manipulate, and move the data later on.
Step 1: Install the Preliminaries
Before jumping straight into web scraping, there are a couple of things you need to do first.
- Create a ChatGPT account. ChatGPT requires users to log in before using the service. So first, log in to your existing account or, if you don’t have one yet, click “Sign up”, and create it.
- Get a text editor. To execute the code, you’ll need a text editor. There’s one already pre-installed on your computer (TextEdit on MacOS or Notepad on Windows), but you can use any third-party editors like Notepad++ or Visual Studio Code. Such text editors tend to have more advanced features and usually highlight functions in different colors for better readability. However, extra functionality might not be necessary, so it’s completely up to you which tool to use.
- Install the latest Python version. If you use an older version of MacOS (12.3 or older) or Linux, Python may be preinstalled on your device. If it’s not, download Python from the official website and install it to your computer.
- Install necessary libraries. Then, install Requests and BeautifulSoup by running
pip install requests beautifulsoup4in the terminal (search for Terminal on MacOS or Command Prompt on Windows).
Step 2: Locate Elements You Want to Scrape
Now, it’s time to gather some information from the target website about the elements you’re going to scrape. Specifically, the CSS selectors defining book names and pricing. ChatGPT needs this information to build a scraper that targets these exact elements.
Visit https://books.toscrape.com/. You’ll see a list of books right away. To get the elements for the scraper, we’ll need to use “Inspect Element”. The easiest way to do this is to right-click on one of the book titles, and select “Inspect.” This action will open the browser’s Developer Tools, and you’ll see the HTML code of the website there.
Then, locate the book title element. Hovering over the code will highlight the area it defines, so you should find it easily. Once you locate the element, right-click on it, select “Copy,” and click “Copy selector.”

Next, paste the copied selector somewhere to save (a desktop sticky note or your text editor) because we’ll need it in the next step. Copy and write down the selector for book prices, too. At this point, you’ve collected all the necessary information to write a prompt for ChatGPT.
Step 3: Prepare a Prompt for ChatGPT
Now, let’s write a prompt for ChatGPT to create a web scraper. A good rule of thumb is to write a clear, well-explained prompt with keywords and phrases that outline everything the chatbot needs to know.
| Prompt question | Instruction for ChatGPT |
| What does ChatGPT need to do? | Write a web scraper that extracts book titles and prices of all books in the target website. |
| What is the target URL? | Target website is: https://books.toscrape.com/ |
| What programming language should it use? | Use Python programming language |
| What libraries should it use? | Use the following libraries: – Requests – Beautiful Soup |
| What elements it needs to scrape? | Defined CSS selectors are:
|
| What are the output requirements? | Save titles and prices in a CSV file. |
A well-written prompt ensures that the response is less error-prone. Think about the task at hand and what questions need answering to build a scraper that does exactly what we need. Your answers will provide instructions for ChatGPT. Now, all you need to do is give these instructions to ChatGPT and get a response! Here’s the result:
import requests
from bs4 import BeautifulSoup
import csv
# Define the URL of the target website
url = "https://books.toscrape.com/"
# Send a GET request to the website
response = requests.get(url)
# Check if the request was successful
if response.status_code == 200:
# Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(response.content, 'html.parser')
# Find all book containers on the page
books = soup.select('#default > div > div > div > div > section > div:nth-child(2) > ol > li')
# Prepare a list to hold the titles and prices
books_data = []
for book in books:
# Extract the title using the specified CSS selector
title = book.select_one('article > h3 > a')['title']
# Extract the price using the specified CSS selector
price = book.select_one('article > div.product_price > p.price_color').text
# Append the extracted data to the list
books_data.append([title, price])
# Define the CSV file to save the data
csv_file = "books.csv"
# Save the data to a CSV file
with open(csv_file, mode='w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(["Title", "Price"]) # Write the header
writer.writerows(books_data) # Write the data rows
print(f"Data successfully saved to {csv_file}")
else:
print(f"Failed to retrieve the page. Status code: {response.status_code}")
Step 4: Review and Test the Code
Even if you don’t know a thing about writing code with Python, I highly recommend reviewing the code once ChatGPT generates it. Take some time to check if your prompt is clear, includes all necessary information, and if ChatGPT followed all your directions.
For example, can you spot a mistake here?

When you try to run this code, it will show you an error. That’s because I forgot to mention that ChatGPT has to import BeautifulSoup for data parsing.
If you run the code and something doesn’t work, you can ask ChatGPT for help – simply write a new prompt by asking to review and edit the code. Always double-check your requirements and, if you see error messages when trying to run the command, define them. You can always add extra information to the prompt, if necessary.
Step 5: Check Parsed Data
In our prompt, we asked ChatGPT to save data in a CSV file. So, the scraper ChatGPT generated should be able to do so after it’s done with scraping and parsing. Once you open the saved file, your results should look similar to this:
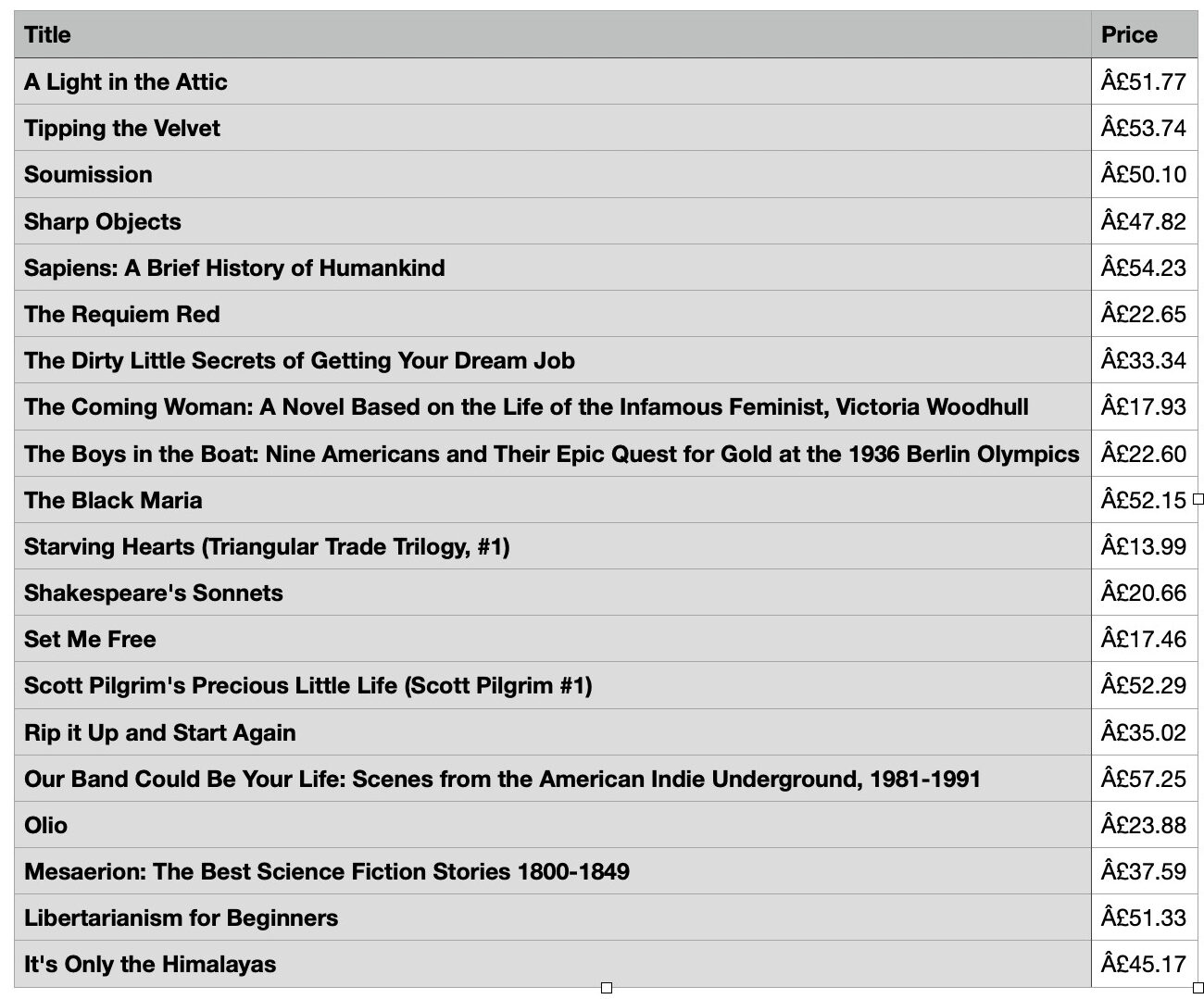
If they do – congratulations, you successfully used ChatGPT for web scraping! If not, go back to step 4 and troubleshoot. Common mistakes can be: forgetting to import CSV to your scraper, you have extracted too much data (this shouldn’t be the case here), or you don’t have enough memory in your system.
Now, you can try to experiment further: rewrite your scraper to extract book ratings or book titles only from specific categories. You probably also noticed that this scraper only scraped the first page only. Try asking ChatGPT to improve your scraper to be able to scrape titles and prices from all 50 pages. The more you practice, the better your understanding of scraping logic will be.
Once you feel confident, you can try advanced data retrieving. For example, you can ask ChatGPT to write a scraper for dynamic content using Selenium. You can use it to scrape flight ticket prices from websites like Expedia or Skyscanner.
However, always keep in mind that actual websites are trickier than the sandboxes. Also, websites rarely enjoy being scraped. For example, scraping Amazon is possible but much more complicated. Nevertheless, whichever website you choose to scrape next, always be respectful to its Terms of Service and robots.txt file, data protection laws, and always follow good scraping practices.
We compiled a list of ideas for you to try.
Advanced Techniques for ChatGPT Web Scraping
The website we scraped is designed to test scrapers, so we didn’t encounter any roadblocks like CAPTCHAs or gotchas. Moreover, all data we scraped was simple HTML content.
However, what if you need to scrape a website that uses dynamically-generated content based on JavaScript? What about bot-protection systems that prevent scrapers from extracting data? To tackle that, you’ll need some more advanced tools. But don’t worry – ChatGPT will still be able to help you out.
Handling Dynamic Content
If you’re planning to do some advanced scraping, a simple web scraper that only handles regular HTML content probably won’t be enough. Most websites nowadays use JavaScript to load their content. It allows you to enjoy things like endless scrolling and infinite loading. These elements, however, are too difficult for simple scrapers to grasp.
Try hovering your mouse on the proxy server icon below. While you can do it and see some extra information about the image, simple scrapers can’t.
There are a couple of ways to scrape dynamic content. One, is to use headless browsers that can execute JavaScript with your scraper. Another – use pre-built tools that can handle and scrape dynamic content in websites.
Using Headless Browsers
A headless browser helps scrapers “browse” the web. Basically, it’s a regular browser like the one you’re using to read this, but it doesn’t have a graphical user interface. So, instead of clicking buttons or typing in URL bars, you interact with the browser programmatically by writing code.
Traditional web scraping methods rely on sending HTTP requests, so they can only retrieve information that is static – text, images, multimedia. Unfortunately, this means that dynamic elements like pop-ups are left behind. In this case, a headless browser can execute JavaScript by rendering it – just like a real user’s browser would. This allows scraping data from dynamic elements. You can use ChatGPT to assist you in writing code for headless browsers like Selenium, Playwright, Puppeteer, or any other.
Writing a Prompt for Web Scraping with Selenium
We can use the same prompt as before, and alter it. Instead of using Requests and Beautiful Soup, let’s ask ChatGPT to use Selenium – a powerful Python library used to automate web browsers. This time, let’s use another sandbox – https://quotes.toscrape.com. We’ll scrape quotes and their authors this time.
Step 1. Install the necessary libraries.
- Run the command
pip install seleniumin the terminal to gain access to a library. - Download the Chrome Web Driver. This Chrome-based web driver is the headless browser that you’ll be able to control with Selenium.
NOTE: You’ll have to copy different CSS selectors for this scraping experiment. Repeat the same steps (using “Inspect Element” and copying data) for getting selectors for quotes and authors in this case.
Step 2. Write your prompt. It should look something like this:
Please write me a Python web scraper using Selenium. The scraper should extract quotes and authors from the target website.
Target website: https://quotes.toscrape.com/
CSS selectors:
- body > div > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span.text
- body > div > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span:nth-child(2) > small
Output: save all quotes and authors in a CSV file.
Here’s how the ChatGPT-generated code should look in your code editor. Notice how the syntax differs from the one we wrote before:
from selenium import webdriver
from selenium.webdriver.common.by import By
import csv
# Set up the web driver (ensure the driver is in your PATH or specify the path)
driver = webdriver.Chrome()
# URL to scrape
url = "https://quotes.toscrape.com/"
# Open the URL
driver.get(url)
# Create lists to store quotes and authors
quotes_list = []
authors_list = []
# Locate the quotes using the provided CSS selector
quotes = driver.find_elements(By.CSS_SELECTOR, "body > div > div:nth-child(2) > div.col-md-8 > div > span.text")
authors = driver.find_elements(By.CSS_SELECTOR, "body > div > div:nth-child(2) > div.col-md-8 > div > span:nth-child(2) > small")
# Extract the text and append it to the lists
for quote, author in zip(quotes, authors):
quotes_list.append(quote.text)
authors_list.append(author.text)
# Close the web driver
driver.quit()
# Save the quotes and authors to a CSV file
with open("quotes.csv", mode='w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(["Quote", "Author"])
for quote, author in zip(quotes_list, authors_list):
writer.writerow([quote, author])
print("Scraping completed and saved to quotes.csv")
Step 3. Find your CSV file, and open it. Your results should sit in a neat table.

Using Pre-Built Tools
Instead of using ChatGPT to build a web scraper from scratch, you can get ready-made scrapers to help with your scraping projects.
Firstly, you can opt for a non-scraping option – some providers offer pre-scraped datasets from various industries. Instead of building a scraper, extracting, cleaning, and parsing data yourself, you can check if there are prepared and detailed datasets for your use case. If there aren’t datasets that suit your use case, and you still need to scrape data yourself, experiment with no-code scrapers. These tools require you to interact with the website, but they translate your clicks into scraping logic. They work by letting you browse, click, and scroll through the site like a regular user, while simultaneously extracting the data based on your interactions.
You can also get web scraping APIs or proxy-based APIs. These tools are made to handle any amount of scraping, and are designed to work with most modern websites. They can handle JavaScript content, create a unique fingerprint, parse extracted data, manage proxies, bypass anti-scraping systems, and more. However, they require some programming knowledge to set up and run, but you can use ChatGPT to help you out here.
Additionally, you can register to use your target website’s API for scraping. Instead of getting the entire HTML document, parsing, and working around JavaScript elements and anti-scraping measures, API lets you get specific and structured data without much hassle. Then, you can send requests with Python – ChatGPT can help you write them, too. It’s important to keep in mind that not all websites offer APIs, they may restrict the data you can access, and more often than not, they come with a cost.
Avoiding Anti-Scraping Measures
While websites like books.toscrape.com love being scraped, most websites don’t. Instead of giving you a hall pass to look around and collect their data, they implement antibot measures. CAPTCHAs and services like Cloudflare protect them from malicious bots. Though, not all is lost if your target website has these measures implemented.
Websites want human traffic because it brings revenue. Bot traffic, however, can overload the servers, preventing real people from accessing the site. If you want to scrape successfully, you need your scraper to look like a real human.
Use Proxies
A proxy server is a middleman between you and the web server. When you route your traffic through a proxy server it masks your original IP address, so the web server can’t detect you. Many proxy service providers offer quality proxies that come in large pools, so you can switch addresses to prevent detection and IP blocks. Typically, real people use residential IPs, so this type of proxy is less likely to be blocked.
Residential proxies come from real devices like smartphones, laptops, or even smart TVs that are connected to the internet via Wi-Fi. By using residential IPs, your requests appear natural, especially when you’re doing some heavy-duty scraping.
Spoof Your Browser’s Fingerprint
Have you ever noticed that websites tend to know it’s you visiting their site, even when you’re not logged in? That’s because your browser’s fingerprint shows some information about you.
A fingerprint is a collection of certain data points – screen resolution, OS, installed fonts, timezone, saved cookies – that help identify you on the web. Regular users like you have pretty detailed fingerprints that are unique, but still quite typical looking. Automated bots, however, tend to have browser fingerprints that either miss human-like information like cookies or precise user-agent strings or are inconsistent, so they stand out.
When you’re building your scraper, it’s important to find ways to spoof your browser’s fingerprint so it blends in. For example, there are Python libraries that can change the fingerprint by adjusting or rotating user-agent strings, or modify parameters like screen resolution and timezone. Antidetect browsers can also be useful – they let you create separate browsing environments with their own digital fingerprints without interlinking them.
Other Tips for Web Scraping with ChatGPT
- Don’t expect it to be perfect. Despite being trained on large amounts of data, ChatGPT is still an automated program, and not a developer. It can provide inaccurate information or code, even if your prompt is brilliant.
- Treat ChatGPT like a junior-level specialist. Think of the chatbot as a capable, but rookie specialist that’s just starting out in the field. Make sure to give clear instructions, and always double-check the result (and your query!).
- Rephrase, reiterate, and regenerate answers. ChatGPT is so popular because it’s very flexible. If you’re not happy with the answer it provides, you can give additional instructions or completely regenerate questions until you like the response. For example, if you decide you want your scraper to be in Node.js rather than Python, you can ask to recreate it.
- Ask follow-up questions. Let’s say ChatGPT helped you write a web scraper with Python, but you don’t understand what certain functions mean. Don’t be afraid to ask “What’s X?” or “What does Y do?” to get a better grasp on what you’re doing. By actually understanding the output, you’ll be able to see if it’s correct.
Conclusion
Although it can’t scrape websites for you, ChatGPT is a great tool that can get you started with web scraping. While not a scraper itself, it can generate code based on your query. Using the chatbot can be the first step to web scraping even if you can’t write code yourself, but it’s important to remember that it’s an automated program that can provide inaccurate information.

{kind=link}