The 9 Best Methods to Bypass Cloudflare When Web Scraping in 2026
Websites don’t like bots crawling around, so they use anti-bot measures like Cloudflare to stop them. If you’re looking to scrape data from Cloudflare-protected websites, you’ll need to know how to bypass it. Let’s find out how to achieve that.

If you ever encountered a CAPTCHA with an orange cloud asking you to check the box that you’re human, congratulations – you’re already somewhat familiar with Cloudflare’s service.
Cloudflare is a company that offers content delivery network (CDN) service to increase web performance and security. Apart from making websites more optimized, Cloudflare protects them from things like DDoS attacks, as well as other malicious and unwanted bot traffic. But what about web scrapers?
Unfortunately, scrapers are identified as bots, and they often get blocked. While Cloudflare allows some verified bot traffic to pass through (i.e. Google’s crawlers that index web pages), bot-protection systems rarely know the difference between good and bad bots. And more often than not, web scrapers are interpreted as the bad ones. But if you’re looking to scrape Cloudflare-protected websites without getting blocked, there are ways to bypass this security layer.
What Is Cloudflare’s Antibot Protection?
Cloudflare is known for its Cloudflare Bot Management designed to shield websites from automated attacks and malicious bots. It provides advanced protection against a wide range of threats, including credential stuffing, web bypasses, and account takeover.
Cloudflare’s Bot Management has a Web Application Firewall (WAF) that uses traffic patterns and advanced algorithms to identify threats and stop malicious traffic from reaching a website’s origin server.
Additionally, the DNS bypass feature differentiates between known good bots and potentially harmful bots. This allows legitimate bots, such as web crawlers, to access a website without being blocked by security measures, but stops suspicious ones.
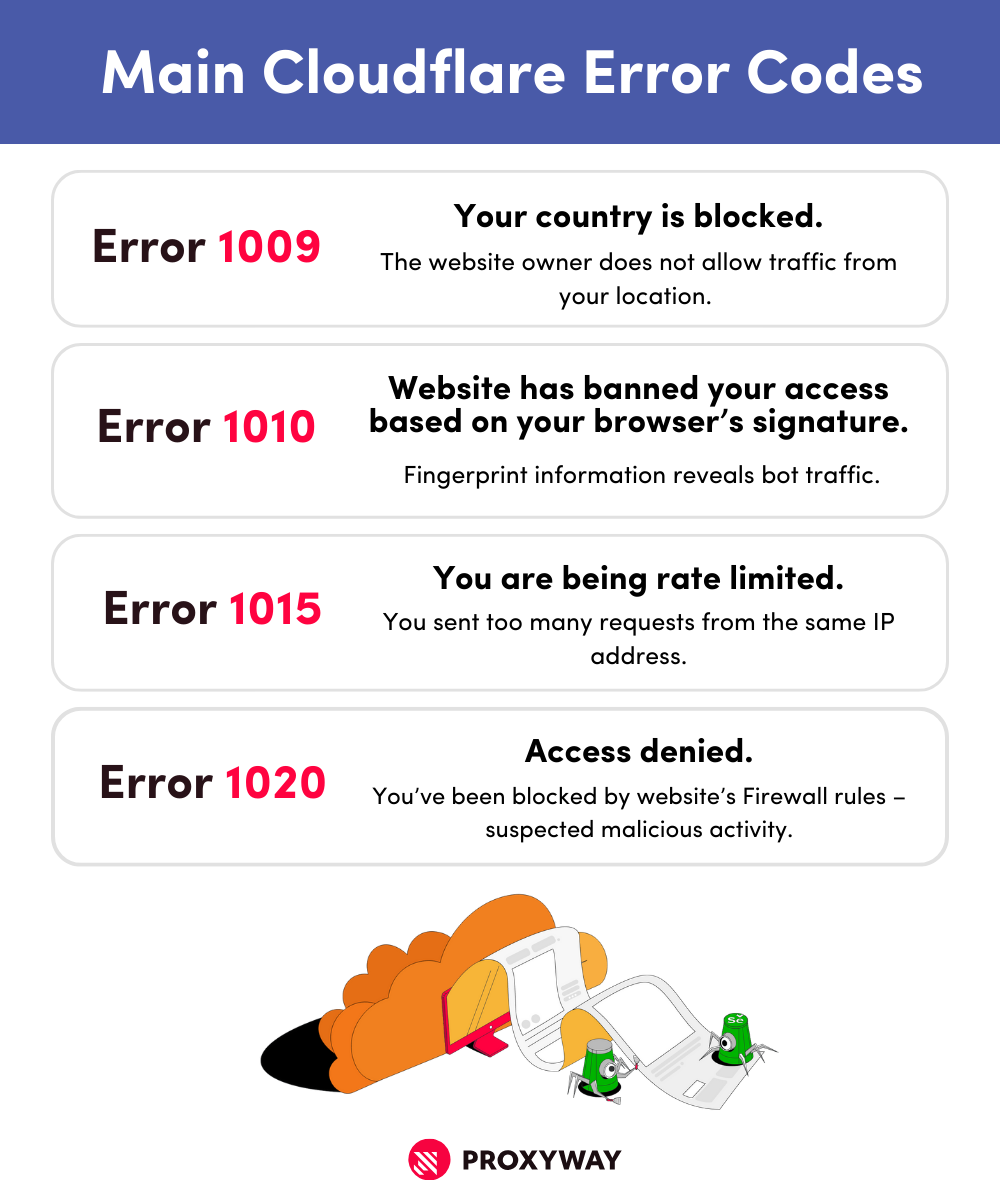
Cloudflare errors and response codes
When Cloudflare prevents you from entering a specific website, you’re going to see an error code which explains the reasoning behind the block. Here are some of the most popular Cloudflare error codes you can encounter.
Cloudflare Error 1020: Access Denied. Cloudflare doesn’t specify the reasons behind this error, but it means that the client or the browser has been blocked by Cloudflare customer’s (website) Firewall rules. Likely, because the Cloudflare-protected website detects malicious activity, considers you a bot, or you’re denied access to a specific page (i.e., admin panel).
Cloudflare Error 1010: The owner of this website has banned your access based on your browser’s signature. Your request to access certain data was blocked because of your browser’s signature. It often happens when scraping tools expose fingerprint information (usually it lacks information or isn’t unique as a human-like fingerprint), and Cloudflare detects it.
Cloudflare Error 1015: You are being rate limited. You sent too many requests from the same IP address, and got blocked. Real user traffic rarely gets limited, so you either need to send requests through different IPs or reduce the amount altogether.
Cloudflare Error 1009: Your country is blocked. A typical Cloudflare error code, but it has nothing to do with your scraper. The error means that the website owner wants traffic only from specific countries or regions, and yours isn’t on the list.
How Does Cloudflare Detect Web Scrapers?
Cloudflare uses two methods to detect web scrapers: passive and active. Passive method refers to using backend fingerprinting tests, while active relies on client-side analysis.
Passive Detection Methods
Cloudflare checks your IP address reputation to distinguish if you’re a bot or a human. For example, humans typically browse the web through residential or mobile IP addresses, as these are provided to them by their internet service providers. In contrast, datacenter IPs are often used by automated systems, like web crawlers or scrapers. So, someone visiting a website with a datacenter address is likely not a human.
Additionally, IPs that were previously used for phishing, scamming, or other malicious activity will be banned. So, if you use a proxy service with your web scraper, make sure the provider offers reputable IP addresses.
Cloudflare also keeps track of bot networks. It stores information about IP addresses, devices, and even behavior patterns associated with these networks. So, it will block IPs and ASNs suspected to be a part of a botnet or give them client-side challenges (“What’s 3+7?” or “Select all red shapes”) to solve in order to prove human activity.
HTTP request headers – client’s browser information – can also be used to distinguish bots from real people. A header from real human traffic has a detailed user-agent string – it defines the operating system, the browser’s version, and other parameters. Also, there are saved cookies, matching IP and geolocation. Bots, however, tend to have a lot of this information missing or mismatched.
Active Detection Methods
To check if the user is not a bot, Cloudflare-protected websites can present Turnstiles – non-interactive CAPTCHA alternatives. These tools are only presented if your traffic looks suspicious. For example, if you have lacking user-agent strings, unusual web interactions, or use datacenter IPs. After Cloudflare checks your parameters and decides you’re a human, you’ll see a “Success!” message after the Turnstile solves itself.

Using proxies or a VPN service increases the chance of encountering Turnstiles. So, if you use proxies for web scraping, keep in mind that the scraper will need to be able to mimic human-like browsing to avoid them.
Additionally, Cloudflare uses canvas fingerprinting to detect automated activity by checking the user’s device class. This class refers to the combination of your browser, OS, and even hardware parameters. It’s defined by three layers: hardware (GPU), low-level software (installed fonts, pixel rendering), and high-level software (web browser). A combination of these parameters creates a unique fingerprint, and Cloudflare can detect if you’re trying to spoof them.
And that’s not all. Cloudflare also has event tracking. It checks mouse activity, such as movements, scrolls, and clicks, as well as what keyboard buttons you press. Typically, humans need a mouse and a keyboard to browse the web, so if your scraper won’t click enough or move the mouse at all, it will raise suspicions.
How to Bypass Cloudflare Bot Management When Web Scraping
There are several ways to avoid Cloudflare’s challenges when web scraping. While no method is perfect, these tools can help bypass Cloudflare rather simply.
Using Headless Browsers
Headless browsers like Selenium or Puppeteer, are regular browsers, just without a user interface. They don’t have buttons, URL bars, and no other elements to interact with. Instead, you use it programmatically. But how does a headless browser help to bypass Cloudflare? There are several advantages to using the tool when dealing with Cloudflare-protected websites.
- You can customize the HTTP browser header. You can design them to mimic real human user-agent string, language selection, cookies, and more. By creating a human-like browser header, you can trick Cloudflare into allowing your scraping bot to successfully operate.
- They make interactions appear human-like. Scrapers are typically very methodical about visiting sites. Humans, on the other hand, are more chaotic, and have distinct patterns. For example, we tend to visit the landing page first, then move to product selection, go back and forth until we choose, and so on. Headless browsers can imitate real browsing patterns and web interactions, such as browsing speed, human-like typing, mouse movements.
- Headless browsers can be fortified. There are several plugins for headless browsers like Selenium and Puppeteer that patch and optimize them to look more human-like. These plugins (you can find them on GitHub) can help spoof fingerprints, modify and rotate user-agent strings, emulate human-like browsing, and more. This is especially important for scraping tasks as it stops fingerprint leaking and fixes parameters that help Cloudflare identify the browser as bot.
Using Proxies
Proxies are intermediaries between you and the web server. They route your traffic through a different IP and mask the original address and location. As mentioned before, humans almost never browse the web through datacenter IPs. So, in order to prevent detection, it’s important to pick residential or mobile proxies for your web scraper.
- Requests appear more natural. When scraping the web, your scraper will be sending loads of requests to the website’s server. You will get blocked if you throttle the server with too many requests. Therefore, it’s a good idea to use different IPs and rotate them. Most proxy services offer sizable IP pools, many geolocations, and an option to rotate proxies. This way, you can make your scraper’s requests appear more scattered and natural – as if they come from different people.
- You can access geo-restricted content. Proxies can help you avoid Cloudflare Error 1009. Setting your IP address to the one allowed by the website will give you the opportunity to access and scrape websites if they are geo-restricted in your actual location.
Using Web Scraping APIs
Web scraping APIs are tools that combine data extraction logic and proxies with little input from you. There are many platforms to choose from, each with different strengths and capabilities. Some platforms will require programming knowledge to set up, while others offer ready-made scrapers for Cloudflare-protected websites (like G2) with integrated proxy service, data parsing, and other beneficial features.
Scraping a Cached Version
Since Cloudflare allows web crawlers, there’s likely an indexed and cached version of the website you want to scrape. So, instead of trying to bypass Cloudflare yourself, you can scrape the cached version.
To scrape the Google cache, add https://webcache.googleusercontent.com/search?q=cache: to the start of the URL you want to scrape.
For example, if you want to scrape Proxyway’s homepage, your URL should look like this: https://webcache.googleusercontent.com/search?q=cache:https://www.proxyway.com/
While this method is a cost-effective solution, it’s the most unpredictable. The cache might be too old, especially if you’re looking for fresh data. Or your target website isn’t cached at all. If you check the web cache page, it will tell you when the last snapshot was made, so make sure this data is still viable for use.

Additionally, some websites like LinkedIn tell Google crawlers not to cache their web pages, so you won’t be able to scrape cache altogether.
Alternative Methods to Bypass Cloudflare
If, for one or another reason, abovementioned methods don’t work for you, you can try some alternative ways to bypass Cloudflare.
- Cloudflare solvers are often used to bypass Cloudflare’s security measures, such as exposing fingerprint spoofing or detecting unhuman-like browsing. There are several Cloudflare solvers and libraries available, some open-source and some paid. However, they often fail to keep up with Cloudflare’s protection methods that are becoming way harder to bypass.
- Cloudflare only blocks requests that pass through their network. Instead, you can try sending a request to the origin server. Call the origin server, find the IP address of the server hosting the content, and then you can send your requests directly, bypassing Cloudflare. However, this method is quite challenging – it’s not easy to find the origin server’s IP address. And even if you do, the host might reject your request.
- If you have the original IP, you can try to request data from the origin server. Once you find the original IP, you can try pasting it into the URL bar, but that might fail because the request lacks a valid Host header that indicates which specific website you want to access. Tools like cURL allow you to specify a host header while requesting the origin server’s IP address. Unfortunately, this method often fails because many origin servers only accept traffic from trusted IP addresses.
- You can also reverse engineer Cloudflare’s antibot system to find the workaround. In essence, reverse engineering is taking the whole system apart to figure out how it works. Knowing a system inside out can help you find loopholes to bypass it. If you have the skill for it, reverse engineering can be a cost-effective solution, especially if you aim to scrape large volumes of data. However, Cloudflare’s antibot system was purposefully made to be difficult to understand and it tends to change frequently, so this approach is definitely not for everyone.
- When you visit a Cloudflare-protected website, you must first wait in the Cloudflare waiting room. It’s a virtual traffic control system that temporarily stops you from accessing the target website. During the wait time, your browser solves challenges to prove you’re not a robot. If all goes well, you’ll be redirected to the web page. However, if you’re labeled as a bot, you’ll be given an “Access Denied” error. You can reverse engineer Cloudflare’s waiting room challenges by checking the network log and debugging the challenge’s script. However, this also requires a very high programming skill level.
Conclusion
There are several ways to bypass Cloudflare, but the one you choose depends on the amount of resources you have, how much scraping you’re planning to do, and even your skill level.
If you’re looking for cheaper options, you can scrape cached versions of websites, try to reverse engineer the antibot system, or get an open-source Cloudflare solver. While not perfect, these methods can be great for the tech-savvy and those looking to save a buck. On the other hand, proxies and web scraping APIs are more expensive but also much more efficient. They are reliable, relatively simple to understand, and the cost usually depends on how much traffic you use.
