Zyte Review
Zyte wraps website unblocking, data parsing, and browser management into one all-encompassing tool.
Zyte is a well-known name within web scraping circles, especially if you need e-commerce data. It used to offer a range of products which are now being consolidated into one API. Powered by dynamic pricing, machine learning, and over 100 engineers, the API is envisioned to become the only tool necessary for extracting data off the web.
In this review, we’ll take a closer look at Zyte API – what it can accomplish, how well, and whether you should use it in place of your own stack or one of the competing web scraping tools.
News about Zyte
-
By Adam Dubois
- Provider News
-
- Conferences
-
- Conferences
General Information
| Country | Ireland |
| Founded | 2007 |
| Web scrapers | General-purpose API with data parsing functionality |
| Other services | Datasets |
| Price range | Cheap-premium |
| Starting price | $1 |
| Payment methods | Credit card |
| Trial | $5 credit |
Zyte is an Irish web scraping company with over 200 employees around the world. It offers web scraping products and data services, mostly focusing on the e-commerce vertical.
Launched in 2007, Zyte can be considered one of the oldest running players in the field. It used to be known as ScrapingHub until a rebrand in early 2021. The company targets a wide range of customers with an emphasis on developers. It also has a strong knowledge of the legal challenges surrounding data collection, which is reflected in some of its policies.
Commercial products aside, Zyte maintains popular open source tools, such as the data collection framework Scrapy, together with several sandboxes for practicing web scraping skills. In addition, it runs one of the biggest annual conferences on web scraping called Extract Summit.
Currently, Zyte’s focus is on perfecting its web scraping API. In 2023, it deprecated the long-running Crawlera (Smart Proxy Manager) and integrated the AI parsing capabilities of another product called Automatic Extraction.
All in all, Zyte can be considered a reputable and established web data company able to rival industry giants like Bright Data and Oxylabs in its focus areas.
Zyte API
Zyte API remains the company’s main product. Though the tool primarily targets developers, it also supports a no-code interface. An early implementation is available for use with e-commerce websites.
Integration
Multiple integration methods available.
| API: ✅ (real-time) Proxy: ✅ | No code: ✅ Other: Python library, Scrapy plugin |
Zyte’s tool primarily integrates as an HTTP API. There’s an endpoint where you POST the API key, URLs you want to scrape, and optional parameters like JavaScript rendering or custom headers. The API receives the request, scrapes the target, and returns the result.
Zyte has an API playground in the dashboard that automatically generates code snippets based on your chosen parameters. For advanced usage, it’s better to use the provider’s documentation.

Zyte has made a plug-in for Scrapy and an asyncio-based Python library as alternative integration methods. Scrapy seems to be the preferred option, considering how well it’s documented (and Zyte’s involvement in the project).
There’s also proxy-like integration that resembles the discontinued Smart Proxy Manager. The current version omits some features like browser rendering, data parsing, and ability to create sessions.
Finally, Zyte is experimenting with a no-code interface on the dashboard. It requires subscribing to a second product, Scrapy Cloud, and is able to scrape e-commerce product pages. You can select the number of requests, scraping strategy (HTTP library or headless), and geolocation. This method automatically crawls the website from the URL you provide.

The interface looks like an interesting foray into no-code scraping. Zyte will surely add new templates with time, and it’s made a smart decision to expose the scraper’s underlying code to engineers who want more customization. However, there’s room for improvements: I don’t really like the requirement for a second subscription, that there’s no easy way to schedule requests or specify which particular pages to scrape (save from one seed URL).
Features
A customizable tool that automates away most proxy management.
| Targets: Universal Locations: 150+ with automatic selection | Concurrency: 500 req/minute Output formats: HTML, PNG, JSON |
Zyte API is a general-purpose scraper, meaning it will attempt to deliver any page you throw its way. This separates it from specialized tools like SERP APIs that focus on one category of websites.
Unlike the now-deprecated Smart Proxy Manager, this API fully manages proxy servers on your behalf. It automatically selects the necessary proxy type and even location based on the page if you don’t override the setting.
The API chooses request headers, device type, and other basic parameters by itself. However, you’re free to provide custom headers, pass on cookies, and create sessions for targets that require it.
In addition, Zyte API has the ability to render a page like a browser. At its basicmost, the feature works like a toggle. But Zyte goes a step further: it exposes interaction parameters like clicking on elements, waiting, and scrolling. One request gets 60 seconds of execution time. In addition, enterprise clients get access to a cloud-hosted Visual Studio Code environment to write full automation scripts.
Zyte limits the number of requests to 500 per minute. It may be possible to increase this threshold upon request.
Structured Data
Three types of structured data from any website.
| Data parsing: ✅ | Supported websites: AI parser for e-commerce, news & job listings |
Zyte API can return structured data. Unlike similar tools that offer parsers for individual targets, Zyte’s AI parser is for all pages with a particular data type. In late 2023, you could extract product pages, news articles, and job postings.
You invoke the feature by including a parameter with the expected data type. Zyte’s machine learning engine processes the page and attempts to return structured data points based on the provider’s schema.
It’s a great approach if you need to process a wide range of websites, but it may not be as accurate as tailor-made parsers.
Pricing Plans
Dynamic pricing based on commitment.
| Model: Subscription, pay as you go Format: Successful requests | Self-service: ✅ |
Zyte API uses an interesting pricing model that calculates the request price dynamically based on multiple factors. It considers website difficulty, the use of residential proxies, headless browsers, data extraction, and compute time for browser actions.
You can influence the price by toggling JavaScript rendering, choosing whether to parse the URL, and configuring page interactions. But some factors will always remain outside your control. For example, the website may get harder to scrape for Zyte, which will increase the rate. In the same vein, it can also become cheaper.
The description can make Zyte’s pricing sound confusing and unpredictable. In some measure, it is. To bring more clarity, the provider has built a dynamic pricing calculator. It lets you enter any domain, tick a few feature toggles, and then it spits out the provisional price.

Zyte’s pricing is also dynamic in terms of plans. You can use the API freely for up to $25 per month and then pay once the billing period ends. Any more than that, and you’ll have to set a spending limit. This requires pre-paying half the limit’s amount at the beginning of the month. The more you choose, the bigger the volume discount you get, up to 70%. This effectively works as a monthly subscription.
Zyte gives $5 of free credit for all customers. If you’re scraping simple websites with no rendering, this translates to thousands of scrapes.
In general, Zyte’s model can be extremely price-efficient for simple websites, but the cost soars once you start enabling the premium features. Here’s an example. If you committed $100. at the end of 2023 this would have given you 715,000 requests to Amazon or 83,000 Nordstrom page scrapes. The latter target has tough protection and requires JavaScript.
Performance Benchmarks
Great results with all tested websites.
We last tested Zyte API in October 2023 for our proxy API research.
We made 1,800 requests to each of seven websites behind tough anti-bot systems like DataDome and Shape.
| Avg. success rate | Avg. response time | |
| Amazon | 95.64% | 3.90 s |
| 100% | 2.16 s | |
| Photo-focused social media network (JS rendered) | 99.61% | 19.78 s |
| Kohls (Akamai, JS rendered) | 99.10% | 29.44 s |
| Nordstrom (Shape, JS rendered) | 99.38% | 20.42 s |
| Petco (DataDome, Cloudflare) | 94.68% | 3.49 s |
| Walmart (PerimeterX, ThreatMetrix) | 96.53% | 2.69 s |
| Overall | 97.82% | 11.70 s |
Zyte API had excellent results with all targets: the success rate exceeded 95%, and it returned results in less than 30 seconds, even on websites that required rendering JavaScript.
In a broader context, Zyte’s performance beat all similar tools from major competitors.
How to Use Zyte
Registration
To register with Zyte, you’ll need to enter your first and last name, email address, and password. Alternatively, it’s possible to sign up using Google or GitHub accounts.
Dashboard
Zyte has a dashboard for interacting with its two products: Zyte API and Scrapy Cloud. Each is contained in a separate section. The API part lets you view usage statistics, use the API playground and pricing calculator, and manage your key.
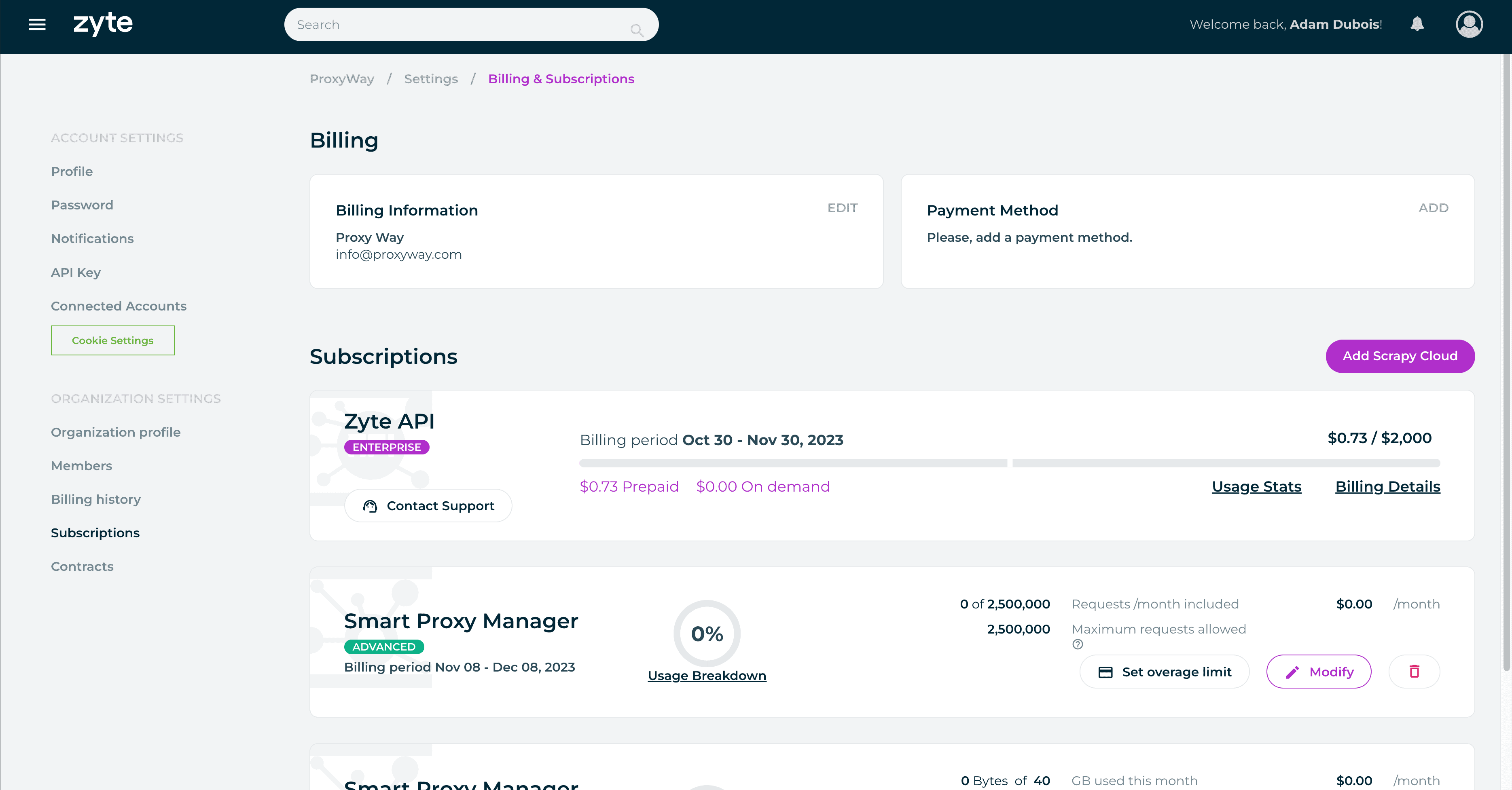
Furthermore, there’s a section for managing account and organization settings, as well as billing. It’s interesting that one account can be associated with multiple organizations, with their own product subscriptions and members. It goes the other way around, too – an organization can host several members with roles. The two roles are a regular member and an owner that can manage the billing details.

Subscription Management
To start using Zyte API, you’ll need to enter a payment method, which is invariably a credit card. Zyte will charge $1 to confirm the card, promptly refund it, and you’ll be able to start using the product.
Zyte supports self-service, meaning that no interactions with people are necessary. There is no wallet functionality; so even though Zyte API can function based on a pay-as-you-go model, you’ll still be paying at a monthly cadence.
Zyte allows viewing your billing history and ongoing expenditure on the dashboard. This information isn’t glanceable – rather, it’s hidden behind several navigation layers. Enterprise clients will also see their signed contracts.
Usage Tracking
Zyte provides detailed usage statistics on the dashboard. You can filter the data based on various metrics: website (all or up to five individual websites), features (such as headless and non-headless requests), request status, parsing type, and even request cost.
The output will be displayed in a graph that can be further filtered by price, request count, or response time. There’s also a table that shows results on an individual request level, including the full URL, response time, and request ID for troubleshooting.
However, the usage tracking isn’t perfect: some data points can be slow to load, and Zyte displays information no older than the last month or the current billing period. In addition, you can’t export the table for easier processing.
All in all, there’s a lot of granularity, but making full use of it isn’t always easy.
For more general information about infrastructure performance, Zyte has a page with uptime statistics.

Documentation
Zyte has detailed documentation for using Zyte API. It provides not only API reference information but also a detailed account of the main features, migration instructions from similar tools, and a step-by-step usage tutorial. You should be able to find everything you need to start scraping with the API.
Documentation aside, there’s also a knowledge base that the provider calls the Support Center. It’s evidently outdated – you’ll find nothing on Zyte API but will be able to read about products that are no longer available.
Finally, you can watch one of Zyte’s many webinars. They cover topics like legal compliance, data maturity, and the use of Zyte API in various scenarios.
Hands-On Support
Zyte’s support system uses tickets that you can submit via the dashboard. The provider gives an SLA of one hour – or eight hours on weekends. Enterprise customers get a special treatment.
This isn’t ideal – not only is the weekend support slow, but it’s also available only via an asynchronous contact method. In other words, you get no 24/7 support or live chat like with many proxy service providers.
That said, another way to get help is by creating a thread on Zyte’s Support Center. But here, receiving a timely response is even harder. One user whose access was removed failed to receive help in four days (!), pointing out that it becomes impossible to use the ticketing system after your subscription ends. The support experience – at least for the person whose woes we’re recounting – was really bad.

Conclusion
Zyte’s API is a powerful tool that works impressively well and offers a rich selection of features. Some, like AI parsing and browser actions, are hard to find in competing offerings.
Zyte’s dynamic pricing is currently another strong point if you’re scraping JavaScript-independent websites. Even then, it remains palatable, though the rates rise ten or more times. That said, expenses here can be harder to estimate than some companies would like.
From the user experience point of view, Zyte treats developers well, especially if you’re already invested in its Scrapy ecosystem. But the user experience can be clunky at times and the customer support was downright exasperating if you need urgent help during weekends or fall outside of the ticketing system.
I’m curious to see how the no-code interface will pan out. It holds great promise for less technically-minded users while still giving engineers access to the underlying code. For now, the implementation works but hasn’t been fleshed out yet.
In summary, I enjoyed using Zyte API and consider it to be a strong choice for anyone looking to simplify their web scraping operations.
Zyte Alternatives
Oxylabs has several web scrapers with data parsing capabilities. They’re scalable, performance, and can structure many e-commerce stores automatically.
Bright Data offers excellent general-purpose and search engine scrapers that integrate as proxies. It also has an IDE where you can built a crawler by yourself.
ScraperAPI’s product is very cheap for simple websites and has developer-friendly documentation that covers multiple programming languages.
Review coming soon
Recommended for:
Engineers that want to simplify their web scraping operations.
