Extract Summit 2024: A Recap
Our virtual impressions from Zyte’s annual web scraping event.
- Published:

Organizational Matters
Like the last two years before it, Zyte’s conference was held physically. For the first time ever, the venue was in Austin, Texas. This spelled great news for Americans, but us Europeans could no longer comfortably watch it – the event took place after usual business hours. But I guess there’s no making everyone happy.
2024’s Extract Summit took place over two days. October 9 was dedicated to live workshops, and the presentations were delivered on October 10. Live tickets for both days cost $330. Virtual attendance was free, but it only included the second day’s talks.
Zyte used Eventbrite for ticket management and Airmeet as the streaming platform. The latter had all the bells and whistles like sections for comments, polls, and QA. I think you could also join virtual discussion tables in-between talks, but I didn’t get the chance to try out this option. The presenters would take questions from the live audience, as well as Airmeet, with Zyte’s CEO Shane Evans moderating.
The main event included nine talks and two panel discussions. Due to time differences, I was only able to watch the recordings. Still, I got the impression that everything proceeded more or less smoothly. After all, Zyte’s been doing this since 2019, so they’ve long become pros.
Main Themes
There was basically one theme explored through various lenses. Not hard to guess – it’s AI: machine learning, large language models, generative AI, all types and flavors. Again and again.
I don’t mean to sound negative; after all, AI has been pushing the envelope in web scraping, and it’s on the top of everyone’s minds while they’re trying to implement it and keep up, all at once. Zyte did a good job composing the line-up, and there were plenty of outside speakers to bring their perspectives.
Something that caught my attention was how many vendors of web scraping tools Zyte accepted to its event. Apify, Browserless, Reworkd can all be considered competitors, yet they were still invited to talk.
The Talks
These are 2024’s presentations. Feel free to jump to the ones that caught your eye using the quick links below.
- Harnessing the Power of Large Language Models for Advanced Data Engineering and Data Science
- Web Data Extraction Mastery: Real-World Implementations and ROI-Driven Success Stories
- A Practical Demonstration of How to Responsibly Use Big Data to Train LLMs
- How We Transformed Zyte’s Data Business with Cutting-Edge AI Technology
- Panel Discussion: The Future of Proxy Technology: Trends and Innovations in Residential, Mobile & Datacenter Proxies
- Distributed Intelligence for Distributed Data
- Panel Discussion: Navigating the Legal Landscape of Web Data Extraction
- Advanced Techniques and Innovations for Extracting Specific Data Attributes from Diverse Sources
- Cache, Cookies, Reconnects: Accelerate Scrapes with Session Management
- How to Feed Large Language Models (LLMs) with Data from the Web
- Enabling Large Language Models (LLMs) Agents to Understand the Web
Talk 1. Harnessing the Power of Large Language Models for Advanced Data Engineering and Data Science
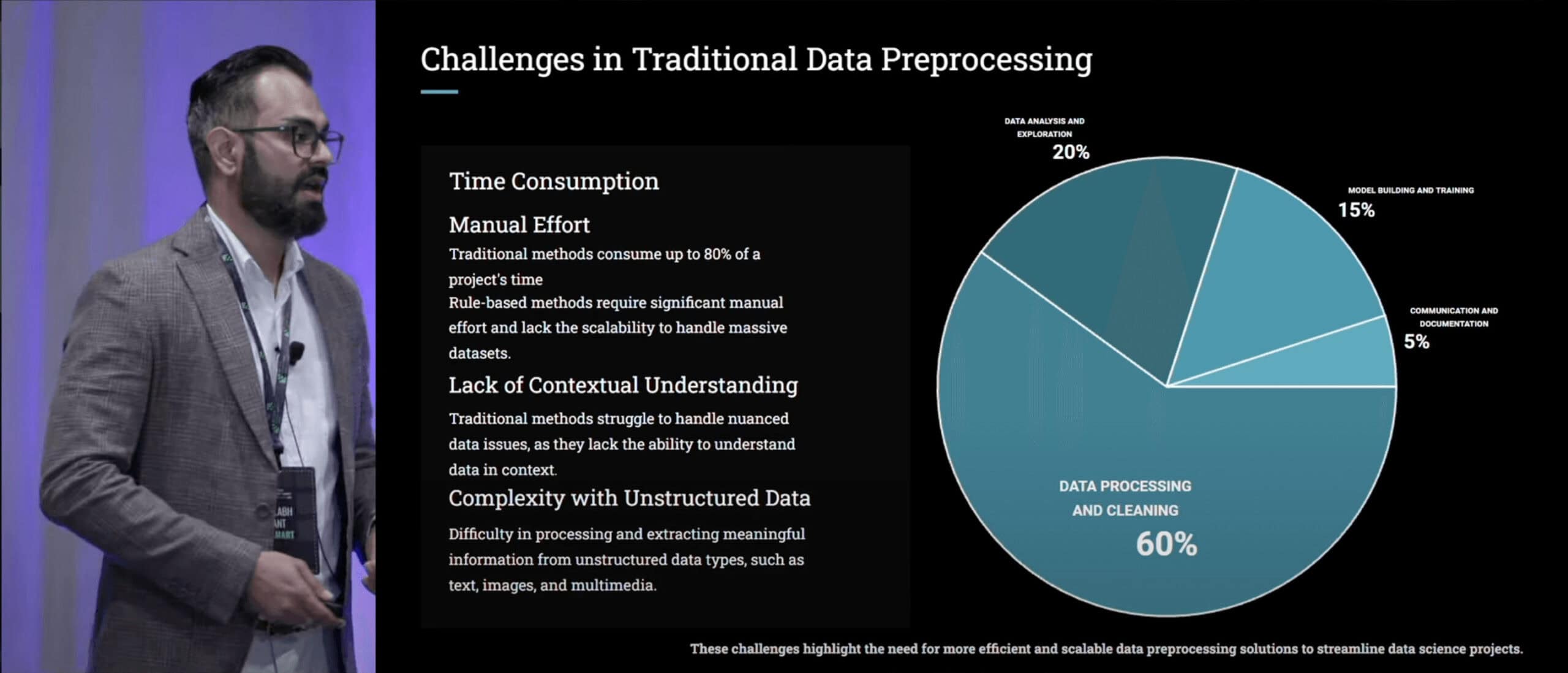
Neelabh Pant from Walmart spoke about his team’s use of LLMs for data cleaning. In an act of extreme generosity for the uninitiated, he decided to begin from the creation of the universe, introducing data processing and even LLMs. But it didn’t take long for things to pick up pace.
In brief, traditional rule-based methods require a lot of manual effort, can’t handle context and unstructured data well. Conversely, these are the areas where LLMs excel. After many experiments, Neelabh built a two-phase system that adds missing values (called improvement phase) and extracts facts from unstructured data (called feature enhancement phase). He provided the implementation details and compared four approaches based on price and effectiveness (spoiler: RAG + agents win).
If you’re in the field of data engineering and spend inordinate amounts of time on messy data, this is the talk for you.
Talk 2. Web Data Extraction Mastery: Real-World Implementations and ROI-Driven Success Stories
John Fraser’s company Parts ASAP scrapes the agricultural product data of several dozen competitors several times a week. He outsources the process to Zyte and, by timely implementing the extracted insights, ensures a healthy but by no means shocking 20% annual growth to the happy board. Sounds… a bit mundane, doesn’t it?
Well yes, but also no. John is what I described to myself as a nonchalant badass – one hand in the pocket, giving a no-nonsense story of how he found a practical use of web scraping to grow his business. It doesn’t push any envelopes or promise you the world. And yet, I enjoyed it a lot.

Talk 3. A Practical Demonstration of How to Responsibly Use Big Data to Train LLMs
Joachim Asare from Harvard University spoke about the ethical pitfalls looming in the LLM training process. These include leaking private information, introducing biases, and ingesting low-quality data, among others. The presenter explored the issues during different stages of training: data collection, fine-tuning, and deployment.
Joachim’s mantra throughout the talk was dump data, ‘dumb’ AI. He provided harrowing examples where a maltrained mental health AI model can advise people to kill themselves, or where Meta’s AR glasses were hacked with terrible privacy outcomes. I don’t dabble in LLM training, so the talk was harder to relate to, but it’s still very relevant for understanding how third-party AI can affect you as the user.

Talk 4. How We Transformed Zyte's Data Business with Cutting-Edge AI Technology
Ian Lennon from Zyte spoke about the problem of horizontal scaling – in particular, the company’s approach to providing high-quality (read: structured) data from hundreds of websites. According to Ian, it’s a combinatorial problem, and AI has allowed Zyte to slash setup costs and onboard customers they couldn’t before.
How exactly? First, by building supervised machine learning models that can parse various page categories. Then, by making them work without browser rendering. Zyte’s final iteration (at this point) allows users to customize the models, by either adding manual code or invoking privately-hosted LLMs.
Zyte’s also betting big on scraping templates that cover all major stages of web scraping: crawling, unblocking, and parsing. I remember the provider introducing its no-code product page template last year – turns out, e-commerce data makes up nearly 60% of Zyte’s business. More templates are coming soon.
Overall, it’s an interesting watch to learn about Zyte’s approach, even if it takes a more salesy angle.

Panel Discussion. The Future of Proxy Technology: Trends and Innovations in Residential, Mobile & Datacenter Proxies
Jason Grad from Massive, Neil Emeigh from Rayobyte, Ovidiu Dragusin from Serversfactory, and Vlad Harmanescu from Pubconcierge sat down for a discussion on proxy servers, managed by Zyte’s Shane Evans. There was supposed to be one more participant – Tal Klinger from The Social Proxy – but he wasn’t able to attend.
The panelists touched upon many topics ranging from IP sourcing, effectiveness of different proxy types, and geolocation challenges to ethics and IP scoring. To my surprise, the latter received particular attention, as more and more clients are turning to services like IPQualityScore for evaluating proxy services. This can be a dangerous (and not always useful) practice, but it serves as an easy signal for IP quality.
The panel had a good balance between providers focusing on residential and server-based proxies, highlighting their perspectives and challenges: for example, geolocation is a significant issue for ISP proxy vendors, less so for peer-to-peer networks. Considering that our website has the word proxy in it, this is a must.

Talk 5. Distributed Intelligence for Distributed Data
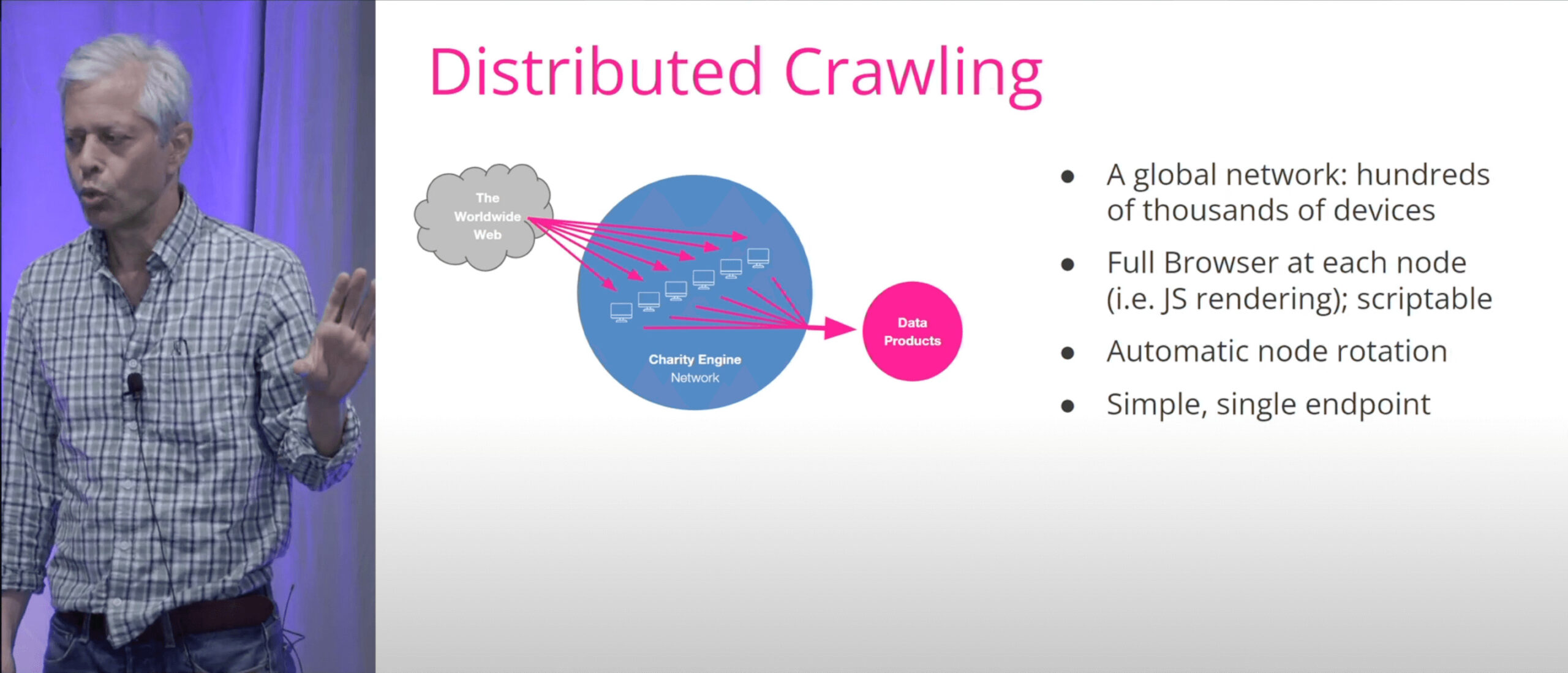
Matthew Bloomberg, co-founder of Charity Engine, spoke about the project and its future directions. We first encountered Charity Engine when testing Zyte’s now-defunct Crawlera tool several years ago; it then served as an IP network for the smart proxy management layer.
Turns out, there’s more to the project than we thought. Charity Engine is a distributed computing platform – so, something like Folding @ Home. It’s able to mobilize not only network resources but also computing power and even full browsers from willing residential users. Matthew gave examples of how the network was used for academic purposes and shared upcoming updates, such as data processing layers on top of the basic API.
My favorite idea was that Charity Engine doesn’t just extract knowledge from the web but also creates new knowledge in the process. By the way, the network is open to any business interested in its capabilities.
Panel Discussion: Navigating the Legal Landscape of Web Data Extraction
Sanaea Daruwalla from Zyte, Hope Skibitsky from Quinn Emanuel (the law firm that litigated the HiQ case), Stacey Brandenburg from Zwillgen, and Don D’Amico from Glacier Network discussed the legal topics relevant to web data extraction. There was a lot to talk about: the discussion lasted nearly an hour and nearly gave me carpal tunnel syndrome from all the notetaking.
Without expanding too much on it, the current legal landscape is super volatile: we had the Bright Data lawsuits, and all the AI cases are buying lawyers their third seaside mansion. The panelists spoke about the applicability of different online agreements, collection of publicly available personal data, how to approach copyright in the context of AI, relevant regulations, and more.
If you’re running a web scraping business or working with LLMs/Gen AI, you should definitely watch this.

Talk 6. Advanced Techniques and Innovations for Extracting Specific Data Attributes from Diverse Sources
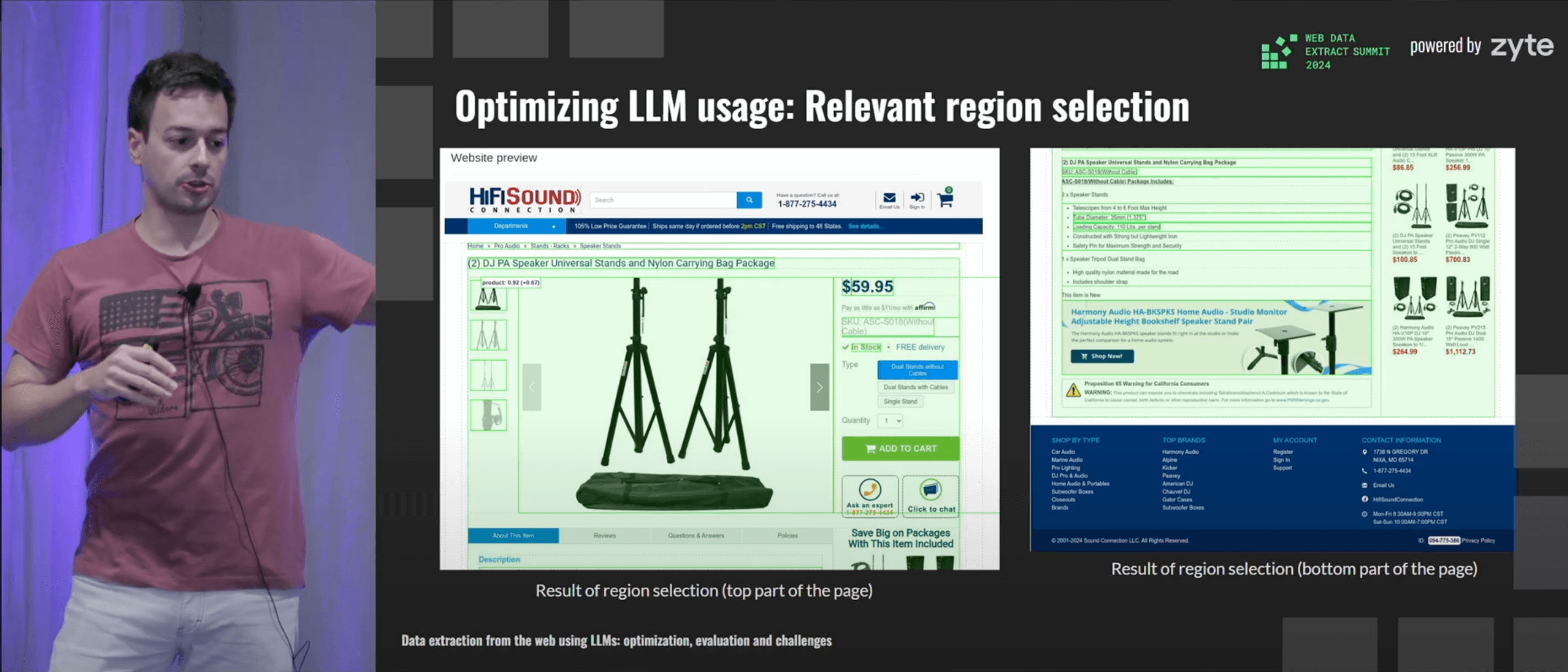
Iván Sánchez, senior data engineer at Zyte, described his company’s use of LLMs for data parsing. It complements and narrows down on Ian’s (Talk 4) high-level overview of Zyte’s AI capabilities.
Iván first introduced the reasoning behind using LLMs at all. He then went on to address the major challenges that arise in implementing the models, such as optimizing token use and devising evaluation metrics. I’ve learned a lot: that it takes relatively few samples to train a model, that you can save money by only selecting relevant regions of a page, and that models become funky way below their maximum token limit. Recommended.
Talk 7. Cache, Cookies, Reconnects: Accelerate Scrapes with Session Management
Joel Griffith from Browserless, a company that runs hardened headless browsers so you wouldn’t need to, described the methods of session management. In particular, he covered caching, cookies, and browser processes, comparing the strengths and weaknesses of each.
It was a highly structured presentation that reminded me of university lectures. If you’re dealing with headless browsers in-house, you’ll learn when to use each method, backed by Joel’s personal experience and some rough implementation examples (which he elegantly called sketches). The process approach received the most attention in QA, and from me as well.

Talk 8. How to Feed Large Language Models (LLMs) with Data from the Web
Another web scraping company took the stage, this time Apify headed by Jan Čurn. If anything, the presentation was a product demo, but that doesn’t mean we got nothing to learn.
Jan spoke a lot about retrieval-augmented generation – its basic mechanisms and importance as the killer LLM application. A bold claim, but one that’s hard to disagree with. He then blazed through some web scraping challenges, setting up the stage for the demo and introducing neat third-party utilities in the process. Finally, Jan showed Apify’s new actors that are made for RAG and include integrations with Pinecone, Langchain, and the like.
Talk 9. Enabling Large Language Models (LLMs) Agents to Understand the Web
One more web scraping company. Asim Shrestha, CEO of Reworkd AI, represents the new generation of data extraction tools that arose together with LLMs. From what I read in their Techcrunch interview, Reworkd’s aim is to capture the long tail of customer needs which competitors like Bright Data currently may not cover very well.
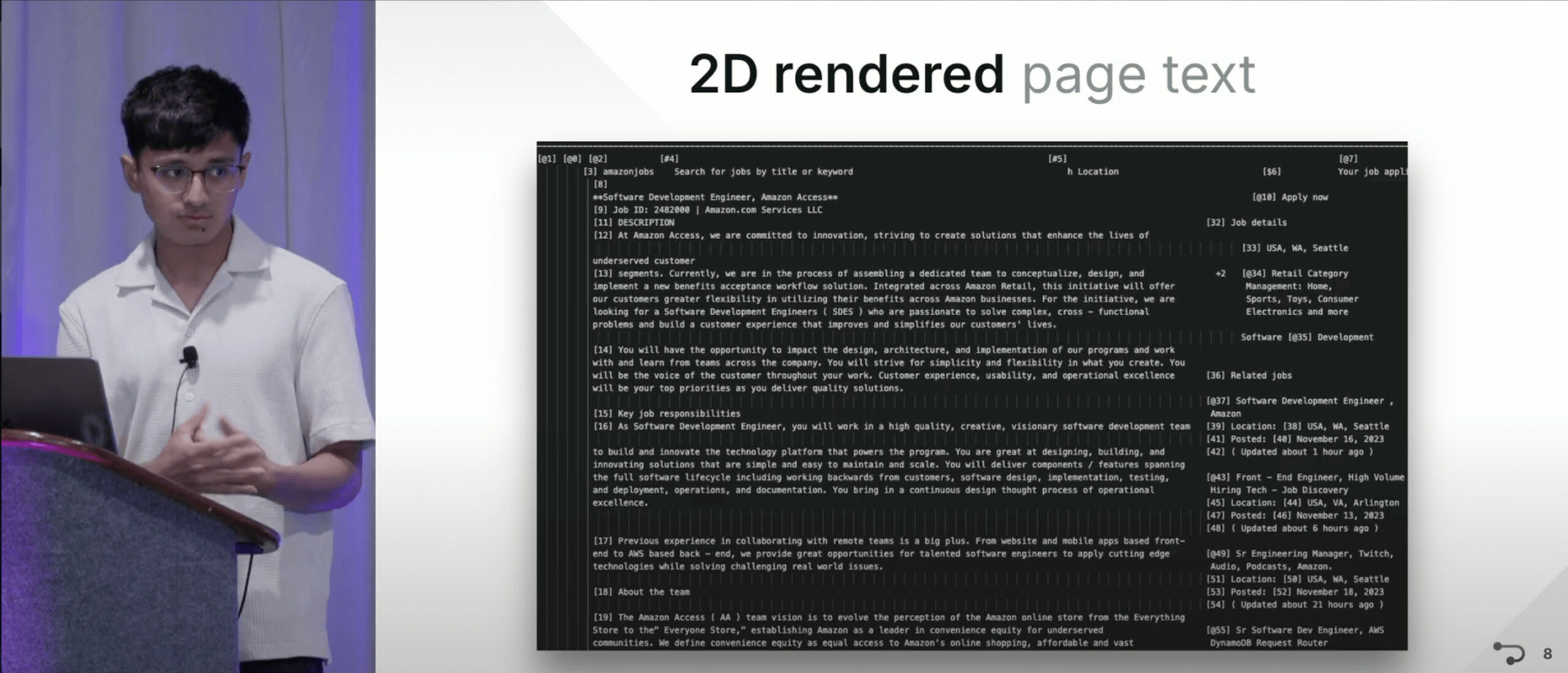
In the talk, Asim described his company’s problem space. It includes finding the right interface to feed data to AI agents, crafting useful prompts, and evaluating the output with real websites. Through constant experimenting, Akim’s team has found unconventional solutions, such as rendering a webpage into a spatial 2D structure with labels for links and other elements. This, and another tool for running evaluations, has been open sourced for everyone to use.
Unfortunately, the audience was tired by this point and didn’t ask a single question. But that doesn’t reflect the quality of the talk – I found it stimulating. Knowing that Reworkd is backed by venture capital, we’re bound to see more innovation come from it.
Bottom Line
That was Zyte’s Web Data Extract Summit – the last web scraping-related conference of 2024. If any of the summaries tickled your fancy, the full recordings are available on YouTube. Thanks for reading!
