OxyCon, one of the the largest virtual conferences on web scraping, has concluded. We were there to witness it all, and now we want to share our impressions with you.
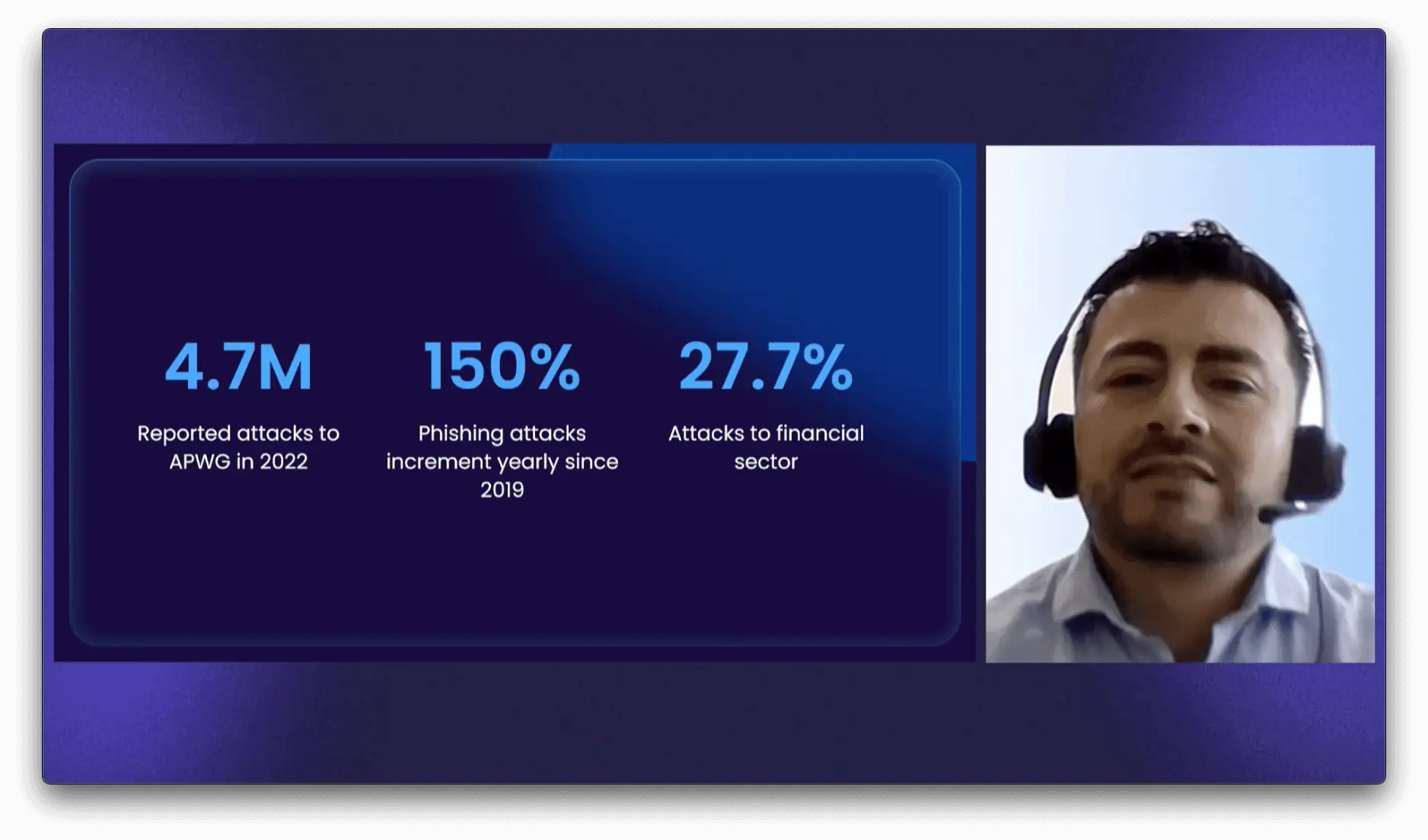
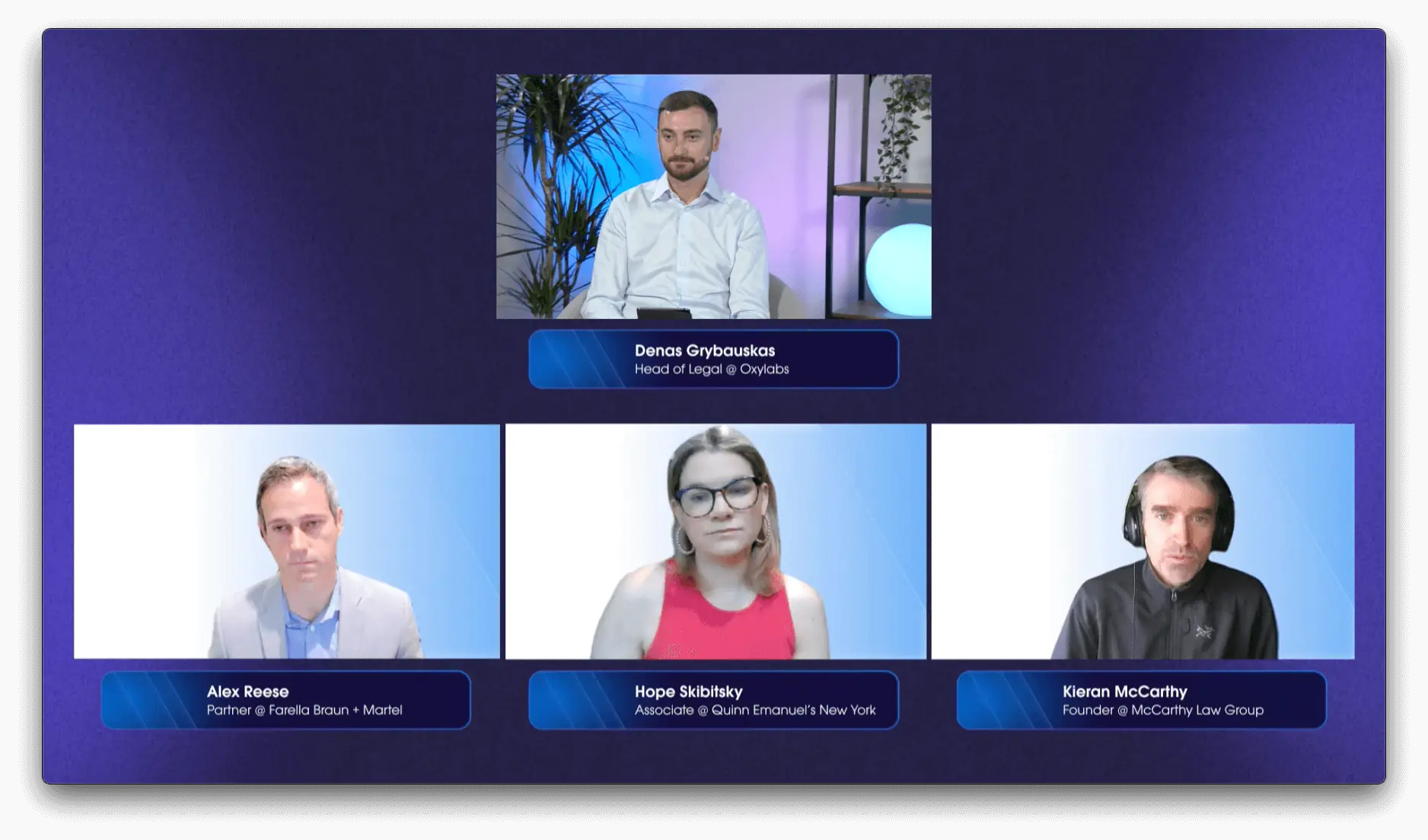
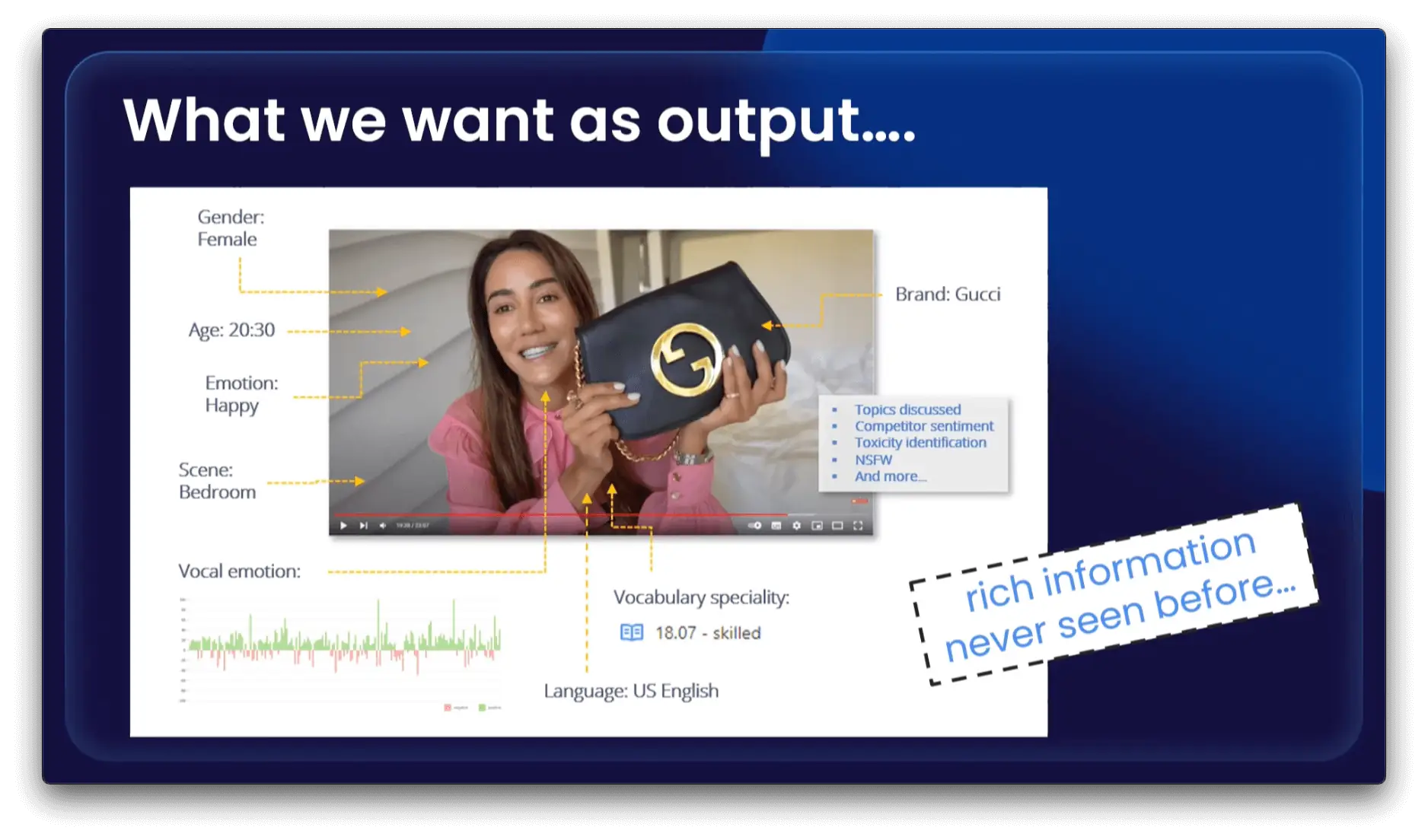
This recap briefly describes the event’s eight talks. They cover a variety of relevant topics that range from large scale web scraping, latest legal developments, to the potential of video data extraction and, of course, AI.
The videos will be
accessible on demand, so you can use our recap to determine whether, and which, of them to watch. Let’s begin!