Zyte Extract Summit 2025 (Austin): A Recap
Our virtual impressions from the first edition of Zyte’s annual web scraping conference.
- Published:

Extract Summit is one of the two yearly events dedicated to web scraping, the other being OxyCon. For the first time, the conference spanned two continents: North America and Europe.
This recap covers the US part which took place in Austin at the end of September. Zyte has made the talks freely available on YouTube, so you can use this article to quickly learn about them before committing.
The Dublin edition is set for early November. We plan to cover it, as well.
Organizational Matters
After flip flopping between Dublin and Austin (in 2024, the venue was in Austin), Zyte decided to simply cover both locations. This spelled great news for audiences that invariably suffered due to time differences. Being located in Europe, we know this pain all too well.
The Austin edition concluded over two days. The first day had five technical workshops run by Zyte. Day 2, dubbed the Main Event, featured ten presentations. Virtual attendance was free, but it only included day two. Live tickets cost several hundred dollars for both days; the sum was meant to cover access to the workshops, the venue – and, of course, tacos.
Once again, being geographically challenged, we were unable to watch the talks live. But Zyte was gracious enough to give us access to the recordings shortly after. Live viewers had Vimeo for the stream and Slido right beside it to ask any questions that arose.
Curiously, there were no panel discussions this year – usually, organizers try to include at least one. And, maybe owing to time constraints, the presenters took very few questions after their talks, often just one or two.
The third thing we noticed was how many industry insiders there were. Aside from Zyte’s staff, we counted five web scraping infrastructure providers and only one company that offers a service based on the data they process (without even scraping it!).
Main Themes
Very much expectedly, the conference revolved around large language models. However, the topic didn’t feel overwhelming, as Zyte struck a good balance sprinkling in flavor presentations. By flavor, we mean case studies or know-how specific to the speaker’s line of business, such as Ovidius’ war stories from working in an IP sourcing company.
The talks didn’t single out data processing which, in addition to natural language input, is arguably AI’s main strength in our niche. We also learned about generating spiders through the use of LLMs and AI agents.
Little attention was given to unblocking – come to think of it, aside from Julien’s woes with scraping Google, the topic was omitted altogether. Maybe companies are less willing to share their secret sauce as the stakes grow, which is a broader trend we’ve noticed over the past year.
The overarching vibe (excuse our Gen-Z) was that many exciting things are coming along, but nothing’s been decided yet – and that there are plenty of opportunities to capitalize on. Pretty inspiring, if you ask us!
The Talks
These are the presentations delivered in Austin. Feel free to use the hyperlinks below if any catches your eye in particular:
- How to Make AI Coding Work for Enterprise Web Scraping
- Why AI Agents Struggle with Web Scraping (and How to Help Them)
- The Technical Reality of Processing 10% of Google’s Global Search Volume
- You Might Want to Reconsider Scraping with LLMs
- Do You Really Need a Browser? Rethinking Web Scraping at Scale
- Web Scraping as Social Practice: Balancing Ethics and Efficiency in a Data-Hungry World
- Balancing Innovation and Regulation in Data Scraping
- Building Blocks of a Web‑Scraping Business
- 99 Problems but a /24 Ain’t One (Except When It Is)
- Data-Quality Framework for User-Submitted Financial Documents
Talk 1. How to Make AI Coding Work for Enterprise Web Scraping
A product demo from the get-go! Zyte brought two heavy hitters, Ian Lennon (CPO) and John Rooney (Dev Engagement Manager) on stage to showcase what the company has been cooking this year.
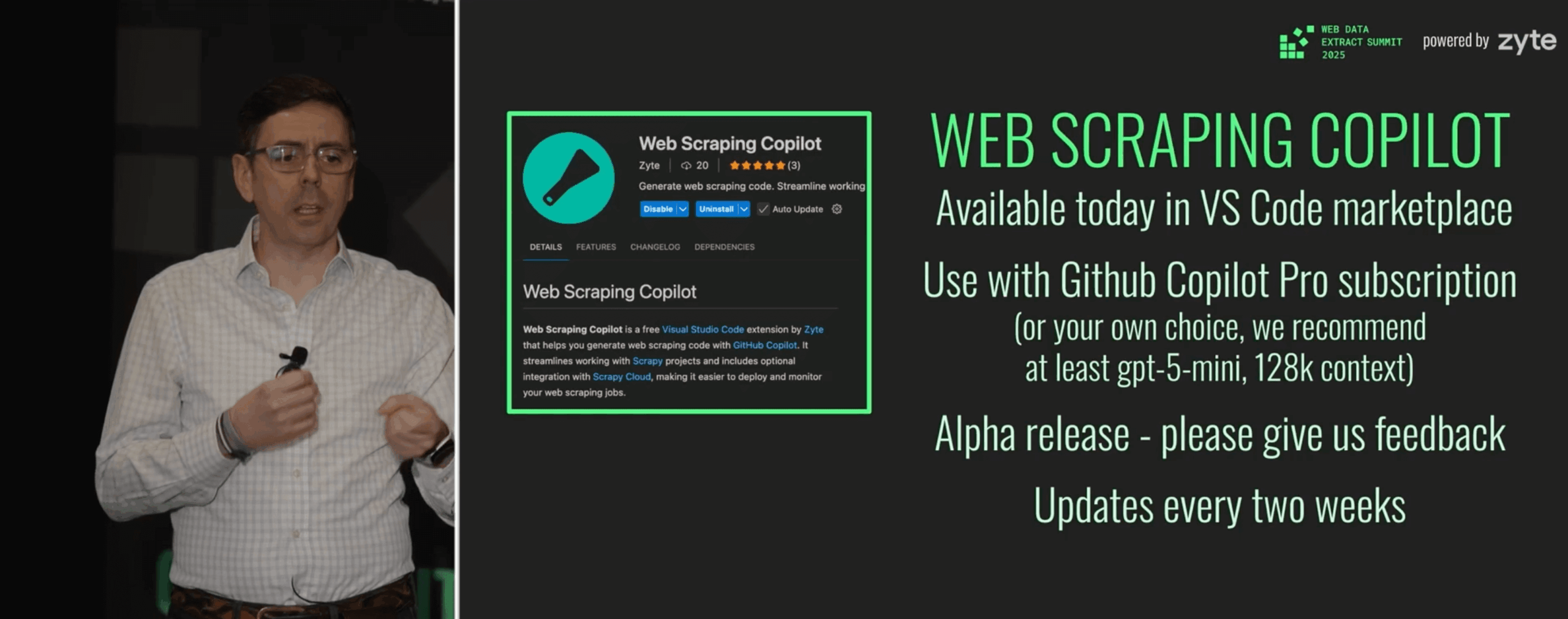
Without beating around the bush, it’s a VS Code extension called Web Scraping Copilot. The tool’s main purpose is to help developers build Scrapy spiders faster by writing objects, fixtures, and other code needed to scrape websites. It achieves this by coupling GitHub’s Copilot and Zyte’s MCP server.
The presentation had two parts. First, John fired up VS Code and promptly built a spider on stage, demonstrating how to fetch and structure several product pages. Ian then took over and gave a broader perspective from the business point of view.
The gist was that instead of making solutions, Zyte aims to create components to help engineers do web scraping well. This is all done with enterprise requirements in mind, in particular determinism, modularity, and ownership of code.
What’s interesting is that you don’t even need to buy Zyte’s API for the extension to work – it accepts any proxy or unblocking tool. The extension itself is free for now, but you may want to get a paid version of GitHub’s Copilot to avoid restrictions.
Talk 2. How to Make AI Coding Work for Enterprise Web Scraping
In the first presentation, Ian mentioned an autonomy scale where AI tools move from assistance towards agency as they progress. Zyte’s Senior Data Scientist Ivan Sanchez took this idea and fleshed it out in the context of AI agents for web scraping.
The first part covered various types of AI agents, drumming up hype with quotes about their adoption. Ian then took viewers back to reality: in their current shape, AI agents kind of suck for web scraping. He gave three slides with challenges and potential solutions before introducing Zyte’s attempt at overcoming the shortcomings.
Wait a minute, are we talking about Web Scraping Copilot all over again? As it turns out, yes. Ian shared more context about the origins of the tool (internal project) and its innards: Copilot relies on mini-agents and MCP sampling to achieve what insular agents can’t. In the end, he teased viewers with a testimonial that claimed to have cut spider building time from eight hours to just two. Impressive!

Talk 3. The Technical Reality of Processing 10% of Google’s Global Search Volume
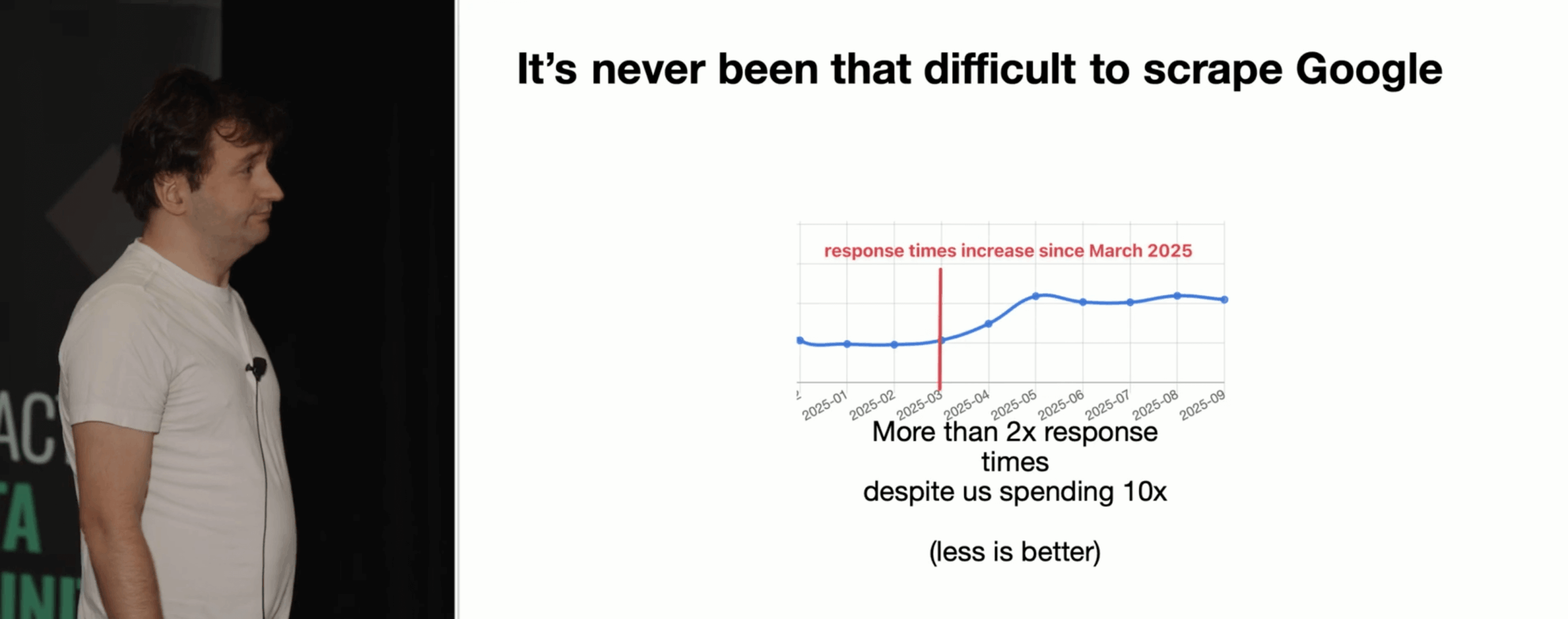
In the third talk Julien Khaleghy, CEO of a major SERP API called… SerpApi, shared the trials and tribulations of scraping Google data in 2025. The takeaway is that despite spending ten times the resources, Google is now twice slower to scrape. Ouch.
What makes this search engine such a naughty target? Besides the infamous move to JavaScript dependency in February and the deprecation of more than 10 results per scrape, Julien’s team encounters: more CAPTCHAs, more diverse CAPTCHAs, more and sometimes permanent (!) IP bans, and JS challenges, among other things.
The presentation gives a fascinating opportunity to learn how a tech giant behaves when it starts taking web scrapers seriously. As a bonus, Julien throws in a performant open source Ruby parsing library – because we’re in this together.
Talk 4. You Might Want to Reconsider Scraping with LLMs
The fourth talk really subverted our expectations. Delivered by Jerome Choo, Director of Growth at Diffbot, it spoke about the performance of large language models in data extraction.
Why did we find the talk so subversive? Well, that’s because Diffbot has been an early adopter and major proponent of machine learning that’s not based on gen-AI. We expected Jerome to demolish LLMs, prying open their weaknesses for all to see. What we witnessed was actually an honest confirmation that AI is pretty darn good at putting data into structures.
Throughout the talk, Jerome walked us through multiple data transformation scenarios, such as extracting news signals about M&As or getting the required information from data processing agreements. The presenter compared various language models and gave useful tips which culminated in this nugget of wisdom: write schemas, not rules.

Talk 5. Do You Really Need a Browser? Rethinking Web Scraping at Scale
Another contrarian presentation – but this time, without a twist. Sarah McKenna from Sequentum, a serial presenter at Zyte’s events, challenged the prevailing tendency to run everything through a web browser.
Sarah’s response was mainly prompted by the rise of AI agents and their reliance on browsers. We have Perplexity’s Comet browser, as well as investments into cloud infrastructure like Browserbase and Browser-Use. However, hype is one thing, and reality is another. Sarah cited works revealing the limitations of LLMs and reminded everyone just how costly and brittle browser-based scraping is.
In-house, Sequentum behaves like any sane (read: bootstrapped) web scraper does: it fires up browsers only when forced to, otherwise extracting necessary identifiers and turning to a lightweight HTTP library. Sarah also spoke about Cloudflare’s gatekeeping efforts, battles over standards, and more, concluding that “the browser opportunity” is still wide open for grabs.
Unfortunately, the slides weren’t formatted properly. But it was still an interesting talk to follow.

Talk 6. Web Scraping as Social Practice: Balancing Ethics and Efficiency in a Data-Hungry World
Rodrigo Silva Ferreira, QA Engineer at Posit, gave a presentation about collecting data responsibly.
Rodrigo Silva isn’t a professional or even habitual web scraper, so his talk was naive at times and often sounded more like a school project. However, the speaker’s sincerity and description of his socially-oriented personal projects left us all the better for having watched it.
The most valuable takeaway for us was that scraping is never just technical, which we sometimes tend to forget. It can have a big impact not only for those doing the scraping, but also the destination, and the people or communities whose data we collect.

Talk 7. Balancing Innovation and Regulation in Data Scraping
Another serial speaker at extract summits, Zyte’s Chief Legal Officer Sanaea Daruwalla, brought viewers up to date with the latest legal developments in web scraping and artificial intelligence. Considering that all we do is scrape data and talk about AI, this one is a must.
To keep this sprawling and complex topic digestible, Sanaea took a brilliant concept of scales, putting innovation on one end and regulation on the other. She then tackled four pertinent topics: public web data, copyright in AI, and the use of personal data.
Compared to 2024, the scales tipped strongly toward innovation, but only when it came to scraping public data. The other cases are much less straightforward. Some of the takeaways were that you shouldn’t collect pirated content, and that the EU takes personal information very seriously.

Talk 8. Building Blocks of a Web‑Scraping Business
Victor Bolu is responsible for ensuring the profitability of his business, Webautomation, and he came on stage to talk about it. To be more precise, he brought a generalized plan for small web scraping businesses, together with ideas for bringing margins closer to a typical SaaS business.
Victor whipped charts and numbers; he broke down the costs of goods, spoke about LTVs, CACs, and other terms found in the books of business management. He gave two case studies, showing why more revenue may not result in profit.
Victor even concocted a three-step margin improvement strategy that revolved around cutting proxy costs, automating support, and pushing upsells with AI. Some of the advice was a little hand-wavy (such as building models that auto-adjust to bot changes), but the talk was delivered from a business and not a technical point of view. This one’s optional.

Talk 9. 99 Problems but a /24 Ain’t One (Except When It Is)
That’s one brain twister of a title. Ovidiu Dragusin from Servers Factory described the daily challenges of an IP broker – or, as he cheekily called them, war stories. We saw Ovidiu last year as part of a panel; however, he really shone having the stage all to himself.
Compared to some other proxy-oriented talks we’ve seen, this one wasn’t heavy on content. (In fact, we probably learned more during the brief QA session.) The speaker opted to share three anecdotes concerning SLAs, disappearing suppliers, and miscommunication with new IP sources. The overarching message was that chaos is the status quo, and that these crazy people wouldn’t have it any other way.
Ovidiu came to entertain and maybe make viewers emphatize with IP brokers. He succeeded.

Talk 10. Data-Quality Framework for User-Submitted Financial Documents
Egor Panlov from Truv closed the conference by delivering a talk about extracting information from financial documents. It’s interesting that his company doesn’t even scrape the web; regardless, data parsing is one of the major problem areas in our field.
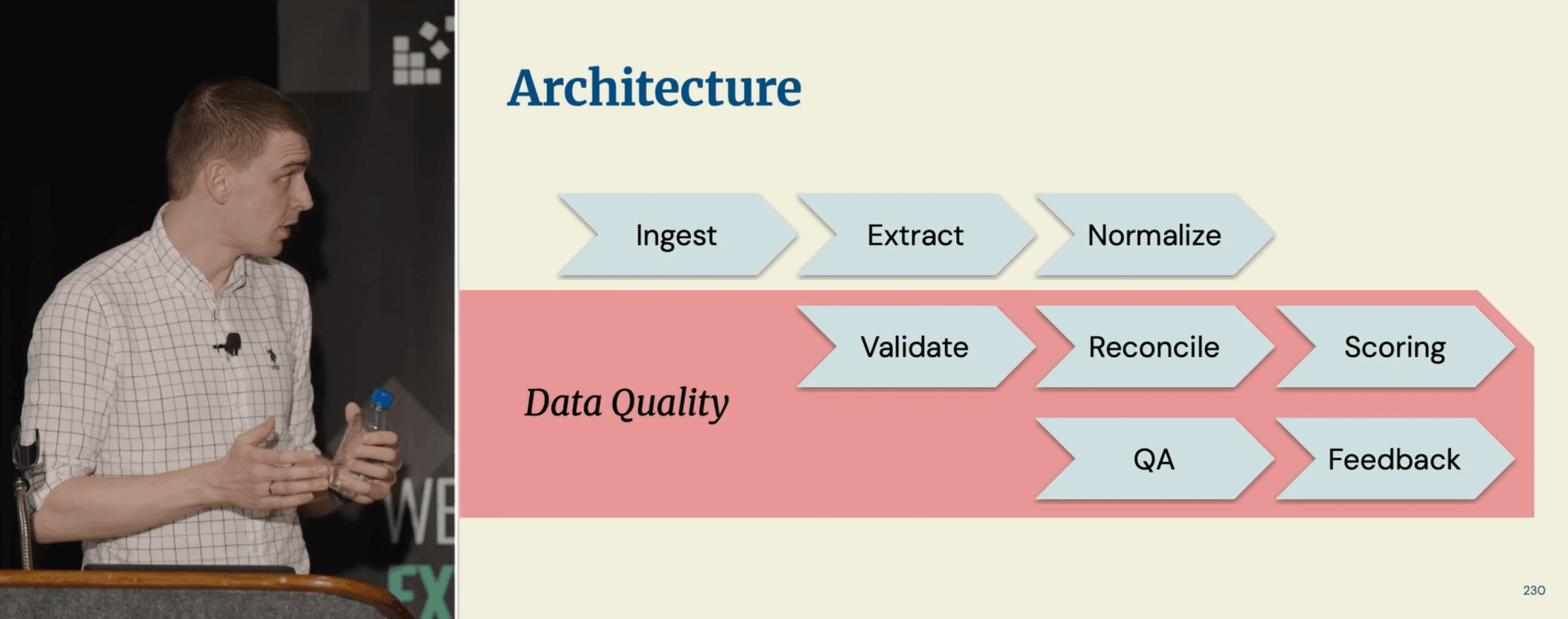
Egor began by introducing income verification documents (like tax statements or pay stubs) and the challenges they bring. These are usually missing or inconsistent records and different document formats. He then walked us through the company’s verification system, showing how they normalize fields, validate data, and make sure that nothing is inaccurate or tempered with. We’re talking about people’s money, after all!
Large language models played a role here as well, naturally within strict guardrails. In fact, they’ve replaced OCR models for something like photos. Egor’s presentation actually received the most questions out of all, maybe due to fewer time constraints. However, we counted over 40 slides, many filled with tables and formulas; so, the talk was more suitable for watching on demand than live. We recommend doing so.
Bottom Line
That was the first edition of Zyte’s 2025 Web Data Extract Summit. If any of the summaries tickled your fancy, the full recordings are available on YouTube. Thanks for reading!
