OxyCon 2025: A Recap
Our virtual impressions from Oxylabs’ sixth annual conference on web scraping.
- Published:

You'll find our coverage of earlier OxyCons and other major industry events here.
Organizational Matters
Oxylabs stayed true to its tested formula and made the conference online only. Anyone was free to attend, as long as they registered beforehand. On the day of the event, the organizer sent an email with a link and a code. It led to a lobby that included a video stream, a Slido widget for questions, and the agenda – a very standard affair.
As a European company, Oxylabs catered mainly to this continent, in particular the British Isles. The schedule used BST as the reference timezone and occupied a timeslot between 12 and 5:30 PM. East Coast Americans were realistically able to watch it, but it was too early for the West Coast and too late for most of Asia.
We always find this fascinating, and the year 2025 was no exception: despite opting for online-only attendance, the organizer still had a venue with hosts and a real audience. We never saw the live attendees, but they could be heard cheering and clapping. We presume these were mostly Oxylabs’ employees.
To make attendance more exciting, Oxylabs ran several quizzes with prizes on its Discord. The server also had a conference chat where presenters could tackle the questions that didn’t make the cut on stage due to time constraints. Believe us – that was necessary, as each talk prompted a surprising number of questions.
All in all, the event went smoothly, and it was clear that the organizers have more or less perfected this format. Our only observation is that it was short – including all the talks, panel discussions, and breaks, OxyCon took only five and a half hours in total.
Main Themes
No surprises here: the hero of this narrative was large language models. We saw them in all shapes and sizes: as parsing assistants, agents, and code generators. Zia Ahmad brought the theoretical chops, the famous Pierluigi from The Web Scraping Club shared some practical applications, while team Oxylabs demonstrated AI in their products.
We’re sure this topic will remain on top of everyone’s minds for the foreseeable future (or until the impending burst of the AI bubble and subsequent collapse of the financial system, if you haven’t had your morning coffee yet). But who can blame them, really?
We loved that Oxylabs managed to fit in two panel discussions. The lawyers discussed large language models from their own perspective, which is always fascinating to follow. The second panel addressed another elephant in the room, which tends to be overshadowed by AI – unblocking. Both are highly recommended, but we’ll talk about them later in this recap.
Our final note here is that OxyCon had not one, but two introductory speeches. The first was given by co-CEO of Tesonet (the company behind NordVPN) Tomas Okmanas. The second, which also took no longer than five minutes, warned about the dangers of gatekeeping and monopolizing data. But we shouldn’t let that put a cloud(flare) over our skies. Sorry, we couldn’t resist it.
The Talks
OxyCon included five presentations and two panel discussions. Feel free to jump to the talks that tickled your fancy. Here’s the 2025 line-up:
- From Chaos to Clarity: Data Structuring in Large-Scale Scraping
- Scaling E-Commerce Data Extraction: From Zero to 10 Billion Products a Day
- Creating an AI-Powered Price Comparison Tool With Cursor and Oxylabs’ AI Studio
- The AI-Scraper Loop: How Machine Learning Improves Web Scraping (and Vice Versa)
- (Panel discussion) Web Scraping and AI: Legal Touchpoints and Ways Forward
- How AI Reshaped My Workflow As a Scraper Developer and Content Creator
- (Panel discussion) Advanced Web Scraping: Techniques to Stay Unblocked
Talk 1. From Chaos to Clarity: Data Structuring in Large-Scale Scraping
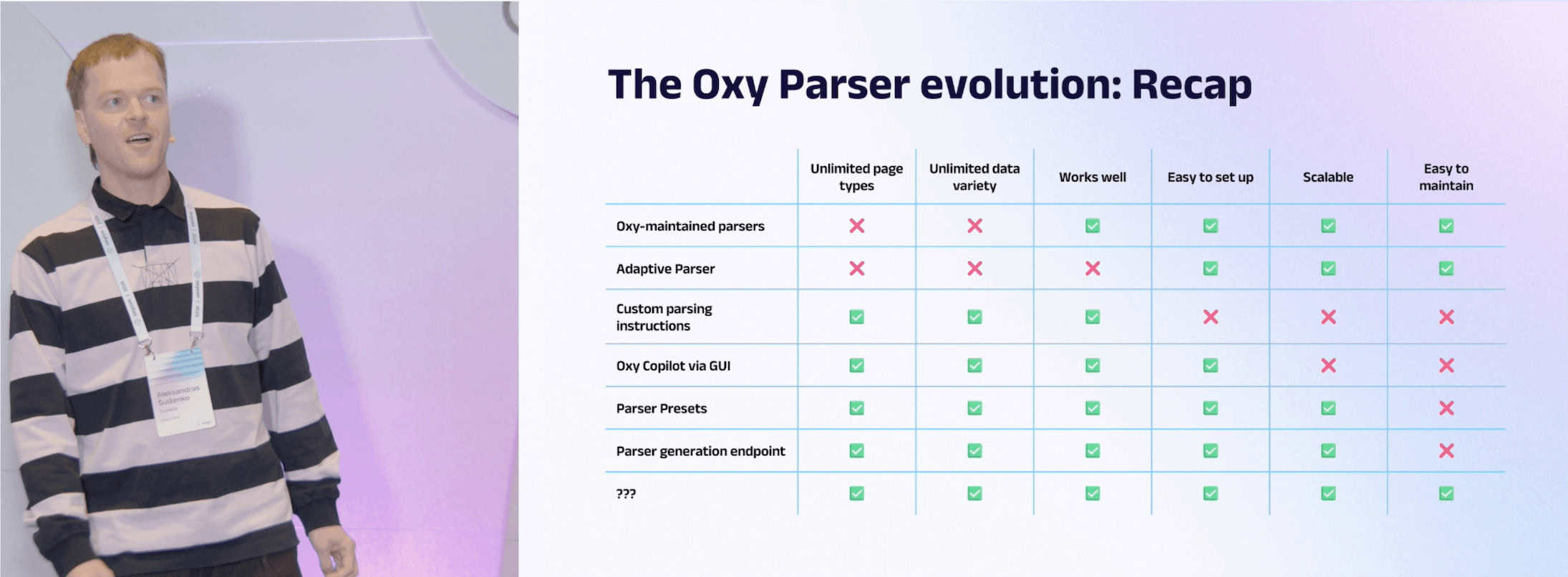
Aleksandras Šulženko, Product Owner at Oxylabs, kicked off the presentations with a walk through history and a feature reveal. He recounted all of his company’s approaches to data parsing, culminating in AI-made parsers that heal themselves.
The company’s road has been long and winding, with seven steps leading to the current implementation. They started with dedicated scrapers, dabbled in machine learning models, and even accepted manual parsing instructions, before arriving at an LLM-based approach. Aleksandras narrated the process very well, highlighting the strengths and weaknesses of each step.
The apex approach generates selectors from plain language prompts, with an optional schema to ensure better accuracy. However, its main breakthrough is that the system can automatically notice once these static parsers break, regenerating them without manual intervention. At this point, the flow of the presentation collapsed a little (because how the heck do you demonstrate self-healing parsers?), but we still consider it a worthy watch.
Talk 2. Scaling E-Commerce Data Extraction: From Zero to 10 Billion Products a Day
A good one. Fred de Villamil, the self-proclaimed CTO of scale-ups, explained how his company NielsenIQ manages to run over 10,000 precisely geolocated spiders for digital shelf analytics. In a nutshell, Fred’s team helps brands like Walmart to understand how their stores perform online.
The speaker outlined the three main challenges he faces, namely coverage, resource management, and anti-bots. He then introduced Nielsen’s strategy for building a process that scales. It involved custom anti-bot tooling, a centralized control center, robust monitoring tools, and even an academy for onboarding new people to his team of 50 web scraping specialists.
Some facts: it takes between six and eight days to build a spider, and the hardest bot protection system to overcome is PerimeterX. You’ll find plenty more where that came from.

Talk 3. Creating an AI-Powered Price Comparison Tool With Cursor and Oxylabs’ AI Studio
Another product demonstration. This time, Oxylabs’ Head of Data Rytis Ulys took the wheel to showcase his company’s new AI Studio. It includes endpoints for scraping and crawling websites, searching Google, and controlling cloud browsers – they’re meant for AI startups and bear a strong resemblance to Firecrawl.
Rytis introduced a hypothetical scenario, where he wanted to open a bike store and needed competitive intelligence. He used Cursor, as well as AI Studio’s crawling and browser endpoints to create a scraper and build two sets of product data from competitor websites within minutes.
The demo was pre-recorded, but it showed what the presenter wanted viewers to witness: that it’s now possible to quickly get data without building parsers, fighting with blocking mechanisms, or even knowing how to code well. The current iteration of AI Studio feels a little like a playground, removed from Oxylabs’ other services. But its utility is evident, and we’re sure the provider will figure out a way to incorporate it into the main product line-up.

Talk 4. The AI-Scraper Loop: How Machine Learning Improves Web Scraping (and Vice Versa)
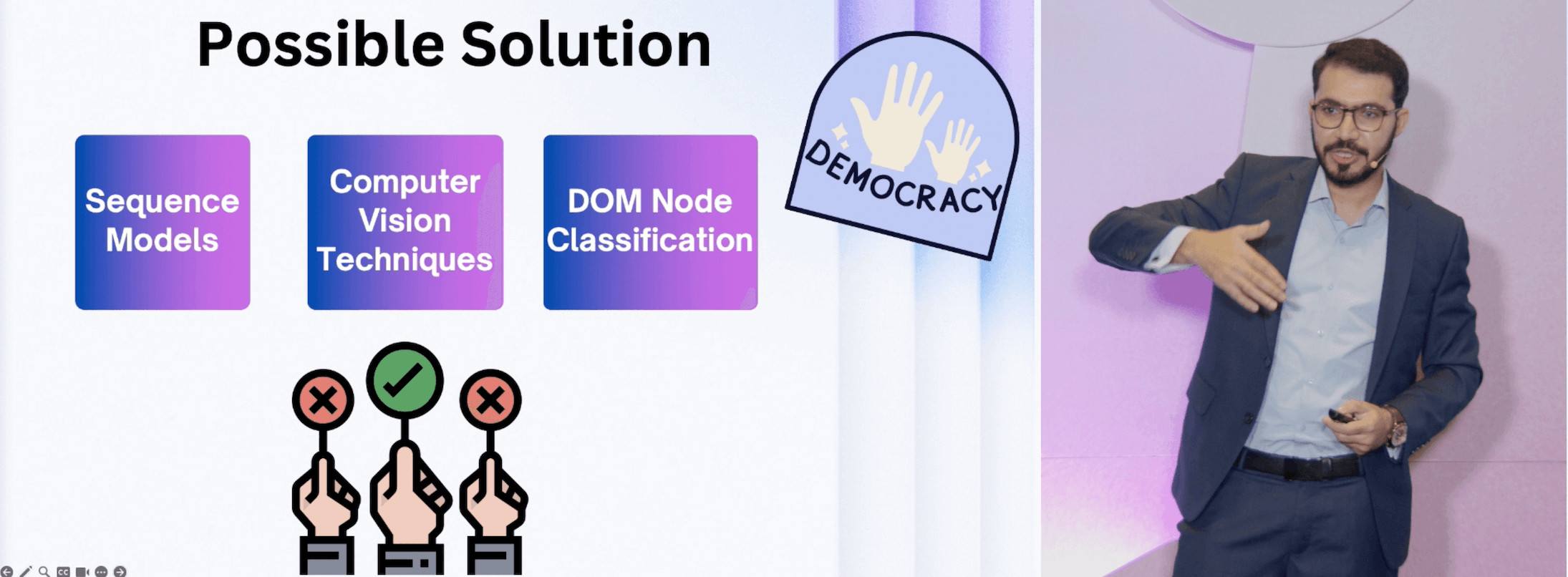
Zia Ahman, Data Scientist at Turing, explored how AI (in the broader sense than only LLMs) and web scraping feed off one another, creating a virtuous cycle of improvement.
The talk started off by showing how web scraping complements ML, which boiled down to stating that language models need a lot of data to work. In the second part, the speaker tried exploring web scraping through an LLM interface, with various results. He then moved on to data parsing techniques, which included computer vision, sequence models for selectors, and using multiple models at once to reach a consensus.
Zia is an educator with many courses under his belt, so we enjoyed learning about the possible machine learning techniques for data parsing and validation. But when it came to data access, we found his arguments somewhat lacking.
Panel Discussion 1. Web Scraping and AI: Legal Touchpoints and Ways Forward
The first panel discussion had three lawyers (Mindaugas Civilka from Tegos Law Firm, Alex Reese from Farella Braun + Martel, and Kieran McCarthy from McCarthy Law Group), one VP of Engineering (Chase Richards from Corsearch), and Denas Grybauskas – also a lawyer from Oxylabs – as the moderator. The panelists have worked on some high-profile cases, such as HiQ vs. LinkedIn, so the line-up here was very strong.
The discussion touched upon quite a few topics. For example, we learned about the main legal questions raised in web scraping, legislation involving AI and the changes it’s brought to the legal world. Much attention was given to the topic of copyright, raising the concept of copyright preemption. The panelists also spoke about how to balance the interests of AI companies and the rest of the world in general. The efforts include Cloudflare’s gatekeeping, remaking the robots.txt file, and more.
It was a brilliant choice to include lawyers representing both American and European legal systems. All in all, we highly recommend watching this panel.

Talk 5. How AI Reshaped My Workflow As a Scraper Developer and Content Creator
The final solo presentation involved Pierluigi Vinciguerra from DataBoutique and The Web Scraping Club. He shared how LLMs helped him to automate time-consuming tasks both as a content creator and a web scraping professional.
In particular, Pierluigi built several helper tools. One of them automatically manages the access level and permissions of paying newsletter users. The second aggregates relevant articles from sources like Reddit and Hacker News, compiling a summarized reading list. After this, Pierluigi showed his LLM-assisted scraping setup which included a blueprint with detailed instructions to ensure that the model will always adhere (to the best of its abilities) to best practices.
Practical examples aside, Pierluigi shared some nuggets of wisdom. The main takeaway is becoming common knowledge, but it’s still worth repeating: language models are amazing for horizontal scaling. But the most striking statement was that AI wrote over 90% of his code last year. We enjoyed watching and recommend this talk.

Panel Discussion 2. Advanced Web Scraping: Techniques to Stay Unblocked
The second panel included Ieva Šataitė from Oxylabs, Juan Riaza Montes from Idealista, Hocine Amrane from Nielsen IQ, and Tadas Gedgaudas, ex-Oxylabs who left to found topYappers. The discussion was moderated by Juras Juršėnas, COO at Oxylabs. We’ll say outright that it’s one of the must-watches of the conference.
The panelists started by sharing what changed in a year. Of course, the big topic was Google cracking down on web scraping. But in general, unblocking has become harder and now requires understanding deep tech. Anti-bot solutions have become a big business and, as the guys from Nielsen love to say, what took two days to unblock now can take two weeks.
On the upside, there’s a lot of activity in open source tools, which are good for up to 90% of use cases. The key is to have a system where you can quickly plug in and test a tool. However, most agreed that it makes no sense to bang your head against the wall – at some point, the better option is to outsource.
As in the previous panel, Cloudflare was on top of everyone’s minds, and it was evident that the incentive system of the web was changing. The panelists shared their other fears, such as new fingerprinting methods like JA4, the increasing resources required to find unblocking techniques, and the possible need to use real devices to scrape.
The discussion addressed many smaller questions: for example, if DataDome is the hardest anti-bot to defeat or if Asian e-commerce stores really serve more fake data than other continents. All in all, despite their concerns, the panelists remained optimistic about the future.

Bottom Line
That was 2025’s OxyCon. We learned a lot, and hopefully, so have you! Go watch the talks while we wait for the second edition of Zyte’s Extract Summit.
