OxyCon 2024: A Recap
Our impressions from Oxylabs’ fifth annual web scraping conference.
- Published:

The anniversary edition of OxyCon is behind us. If you didn’t have the chance to participate, or simply want to read our detailed summary, these are Proxyway’s impressions from the event. The presentations are available on demand, so you can always watch the ones that caught your eye.
General Information about 2024’s OxyCon
Like last year (and, as far as I remember, most years before), OxyCon took place online. However, there was one big change: all presentations were delivered in real time. There was also a live audience in the background, I suppose primarily the company’s employees, who would sometimes react or cheer.
Some of the presenters were obviously dealing with nerves, and hiccups did occur. But this setup made the conference more human and less like Apple’s eerily robotic keynotes.
Otherwise, the logistics changed little compared to previous iterations: you registered (for free), received an invitation email, and logged in to Oxylabs’ platform with an embedded video player and a Slido widget for questions. Those who wanted to discuss more, or more in-depth, could visit the provider’s Discord server.
Introduction aside, 2024’s OxyCon featured six talks and a panel discussion to conclude it. All in all, the event proceeded smoothly and according to schedule.
The Talks
These are 2024’s presentations and panel discussions. You can jump to the talks you’re interested in using the quick links below.
- Introduction: Web Scraping Trends
- Ensuring Scalability in Data Collection: Key Components, Challenges, and Advancements
- Human-Centered Approach to Streamlined Data Gathering
- Imitating Real User Behavior With Mouse Movements
- Harnessing Gen AI for Data-Driven Answers
- AI-Powered Public Web Data Collection at Scale
- Legal Compliance in the Age of AI
- Panel Discussion: Advanced Unblocking Strategies
Introduction: Web Scraping Trends
A fast one. Gabriele Montvile, CCO at Oxylabs, outlined three major trends impacting web data collection. They’re well-known for industry insiders, so there’s no harm in spoiling them for you: AI, ethics, and advancing anti-bots. The interesting part was the supporting material, which included survey data, AI use cases and challenges. Ten minutes well spent.

Talk 1: Ensuring Scalability in Data Collection: Key Components, Challenges, and Advancement
Zydrunas Tamasauskas, another C-level face at Oxylabs, spoke about web scraping pipelines, implementation strategies of proxy servers, headless scraping, and beyond. The title doesn’t make it clear, but this presentation is primarily about proxies. You’ll learn how to choose the appropriate type and implement several load balancing approaches. Some takeaways: desktop residential IPs are the best, and managing sessions between proxies and headless browsers is its own circle of hell.
All in all, a useful talk. We were mentioned as well, so of course you have to watch it now!

Talk 2: Human-Centered Approach to Streamlined Data Gathering
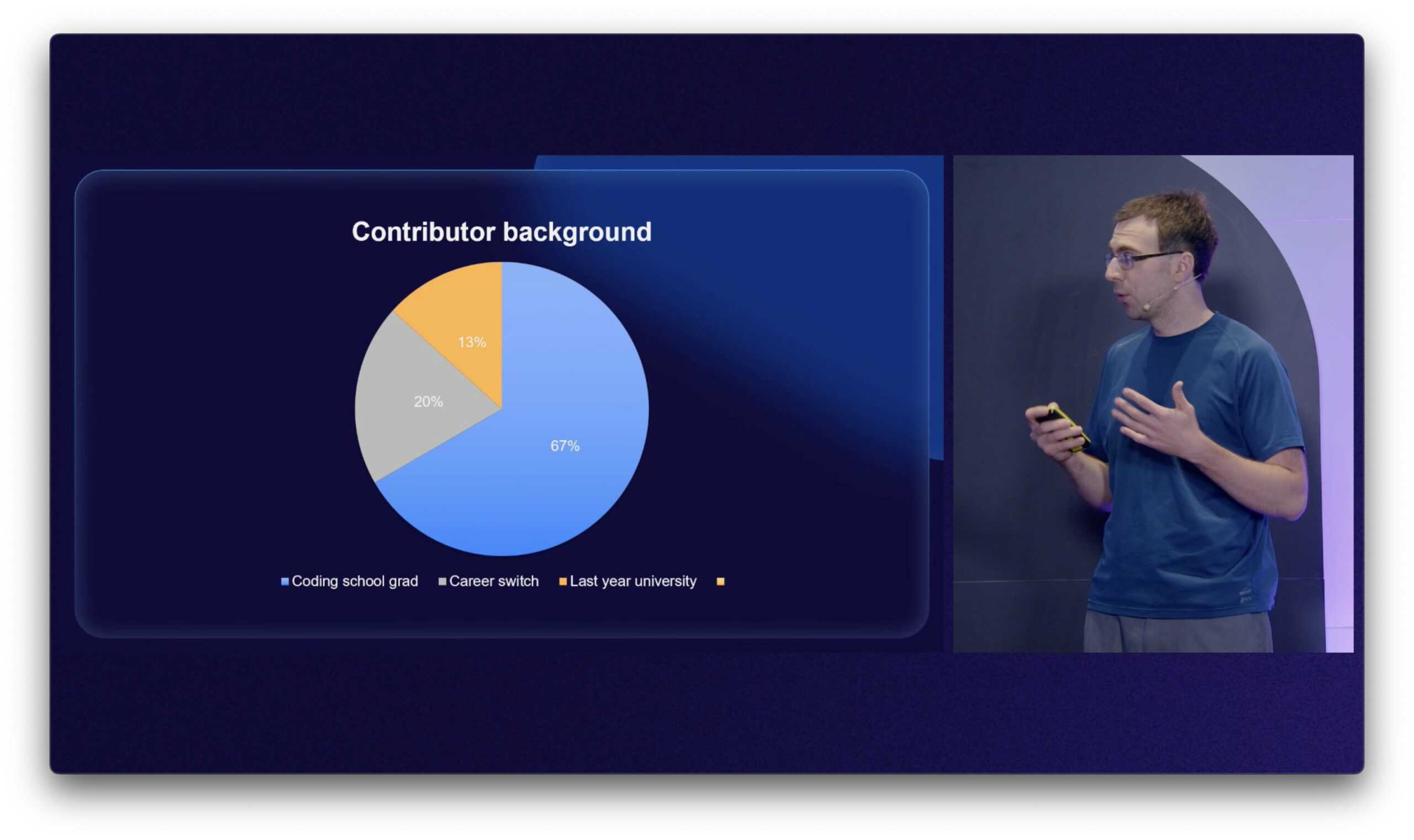
Vilius Visockas from CityNow, a Lithuanian real estate intelligence website, disclosed (let’s sensationalize this a little) how he’s able to scrape nearly a thousand local sources with a small team of 3-4 people. In a wonderful synergy of capitalism and engineering, Vilius chose the only reasonable approach: he built a pipeline management platform, implemented some fail safes, and hired code school grads to mine experience and earn some cash.
Vilius talks about the challenges of keeping the system abuzz. Among other things, this involves maintaining and optimizing schemas, as well as ensuring satisfactory results from contributors with different backgrounds and generally little programming experience. But to me, the real beauty lies in the idea itself and the self-interested social value it provides.
Talk 3: Imitating Real User Behavior With Mouse Movements
A practical boots-on-the-ground presentation that, according to feedback, made at least several viewers’ days. Tadas Gedgaudas from Oxylabs shared his know-how on dealing with mouse-based detection methods.
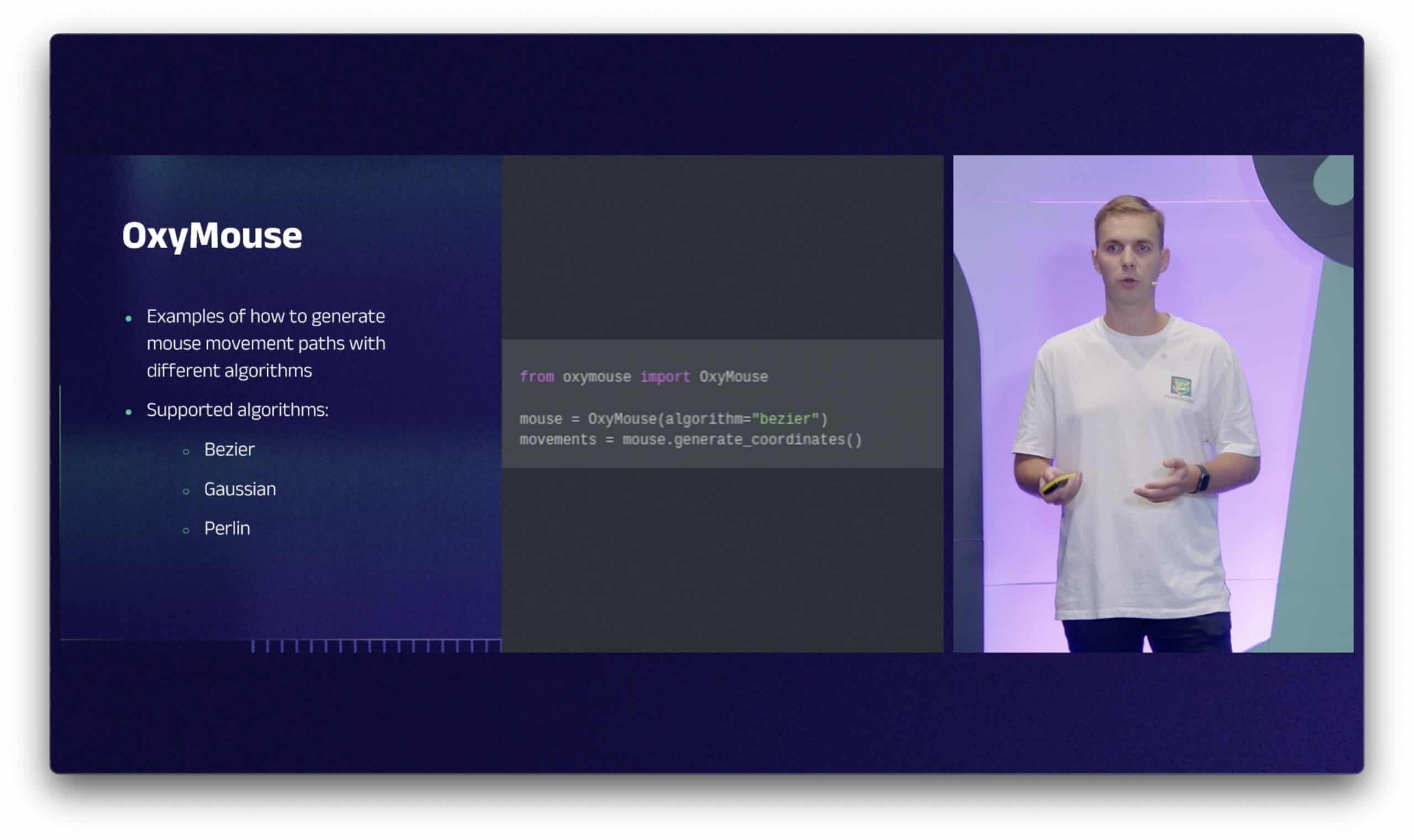
The presenter dedicated the first part to establishing whether websites actually track mouse movements. (Examples from the wild and his own personal weeks-long goose chase to unblock a website prove that they do.) He then showed how to verify this with the browser’s dev tools and went through the pros and cons of three major mouse algorithms: Bezier, Gaussian, and Perlin. Finally, Tadas introduced an open source library made by Oxylabs that can implement any algorithm with a few lines of code.
My biggest gripe is that due to time constraints we were all left hanging: why use anything other than Perlin? But that was probably answered on Discord…
Talk 4: Harnessing Gen AI for Data-Driven Answers
Brace yourselves – we’re entering the AI zone. When Paul Felby (Adthena) started by demonstrating a chatbot, my first thought was, “Oh no!..”. But it turned out there was more to the talk than met the eye: in particular, how to ensure accurate answers and not make LLMs implode when working with a database that ingests hundreds of millions of SERPs per day.
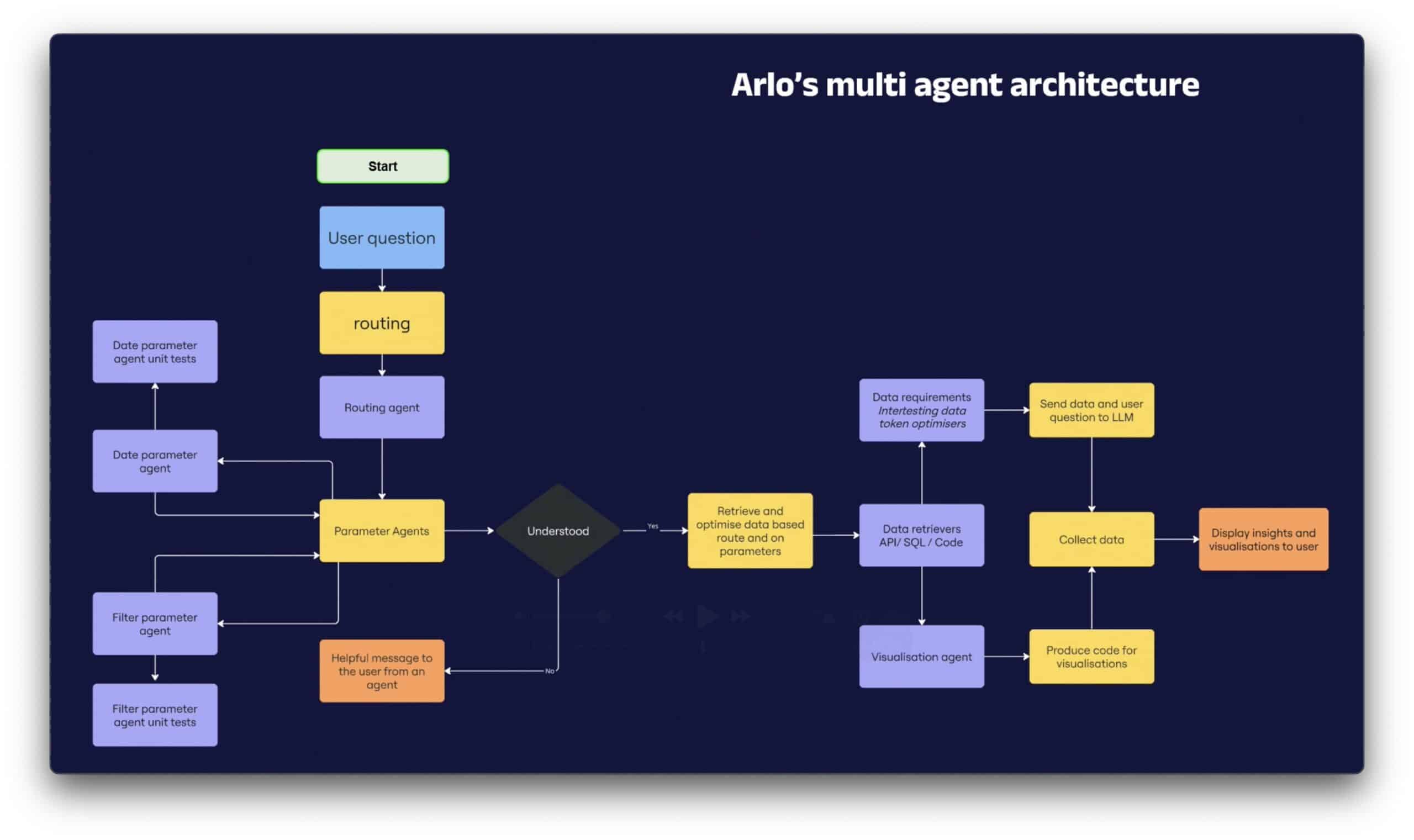
Paul had multiple tricks up his sleeve. Some involved getting the LLM to generate proper queries, either directly in SQL or by adding a semantic layer. Others dealt with creating a team of agents, each performing their own task – even QA. There were layers and layers of AI, which all somehow worked together. The result: a chatbot, but not quite what we’ve grown to expect. Everyone’s working on AI now, so I’m sure you’ll find something to take away from this.
Talk 5: AI-Powered Public Web Data Collection at Scale
The commercial break of the day. Aleksandras Sulzenko from Oxylabs laid out the web data acquisition pipeline, then proceeded to talk about the challenges of each step and how Oxylabs’ tools can make it hurt less. That would be pretty much it, but Aleksandras also made a product announcement: the web scraping API was getting AI functionality called Copilot (how original).
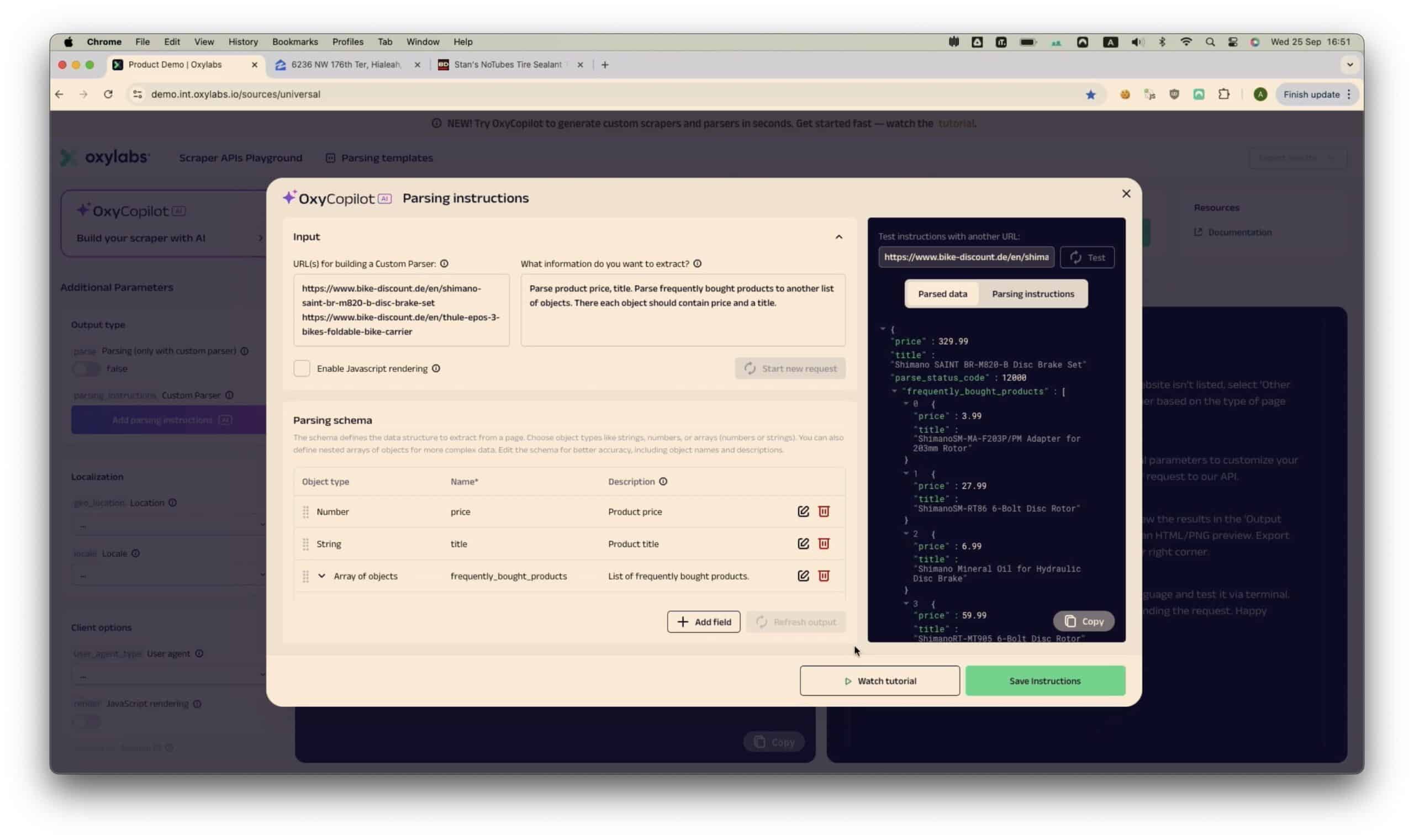
Alright, so it’s something to work with. And the implementation really did prove fascinating: the feature generates API queries from natural language instructions. The real utility here is that Copilot can also create custom parsers with a modifiable schema and visual interface for fine-tuning. Many competitors use AI to directly interact with the page, so this approach is highly practical, albeit somewhat more manual and less resilient to changes.
In brief, watch the talk if you’re in the market for scrapers – or you’re trying to create a competing service of your own.
Talk 6: Legal Compliance in the Age of AI
Nerijus Sveistys, senior legal counsel at Oxylabs, went through the risks, regulations, and relevant lawsuits pertaining to AI. It was more of an overview rather than directly applicable guidelines. Sorry, AI startup founder – you’ll still have to hire a lawyer.
Not keeping track of the legal environment too closely, I learned that the EU already has a regulatory framework, China enacts laws for particular issues, and the US lacks a uniform approach for now. I also saw how many lawsuits are taking place, mostly over copyright issues. My favorite example was the bathroom-invading Roomba surveillance system. A solid talk overall.

Panel Discussion. Advanced Unblocking Strategies
The discussion included Hocine Amrane from Dataimpact, Paulius Gerve from Oxylabs, Jonny Smyth from Ceartas, Brecht Stamper from Lighthouse Intelligence, and Carl Erkof from Wiser Solutions. The host was Juras Jursenas, COO at Oxylabs. Quite a crowd.
It took over 40 minutes, so I’m not sure I’ll be able to recount everything. I suggest just go and watch the discussion – it’s worth it. Some of my notes to give you a taste:
- One of the biggest concerns of the participants was the commercialization of anti-bot software. Specialist tools are more robust, and these companies have marketing people to proliferate.
- We’re finally starting to see detection methods like Canvas fingerprinting put to use. There are more techniques waiting to be exploited, such as local storage.
- Anti-bot research, and much of unblocking, is still done manually, and success relies on human error (which is surprisingly frequent).
- To be successful in this game, you need patience and willingness to butt your head against the wall until it gives.
Fascinating stuff.

Conclusion
That was it for this year’s OxyCon. Did you find anything interesting? The videos are available on demand. And now, we’ll be waiting for another major industry event which is right around the corner – Zyte’s Extract Summit.
