How to find element by id using Selenium
A step-by-step guide on how to find element by id using Selenium.
Important: we’ll use a real-life example in this tutorial, so you’ll need Selenium library and browser drivers installed.
Step 1. Write your first Selenium script.
NOTE: We’ll be using Python and Chrome WebDriver. You can add the Chrome WebDriver to the Path.
Step 2. Now let’s find the following element by its id for any book listings by inspecting the page source. We’ be using books.toscrape.com in this example.
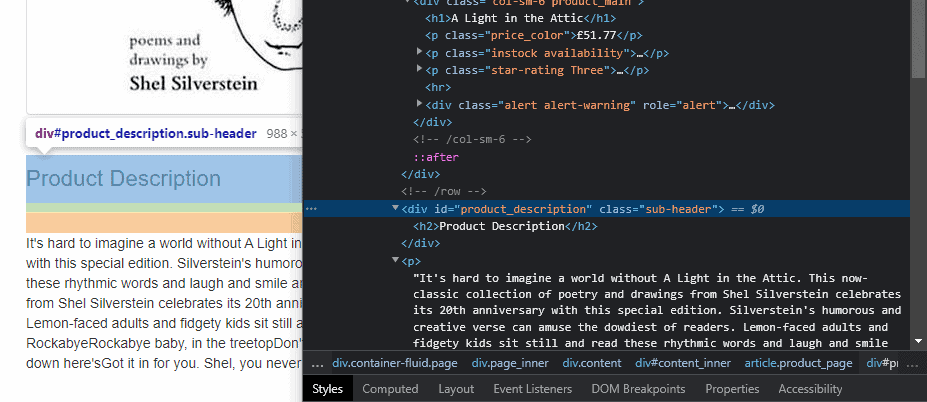
Firstly, you need to import the By selector module
from selenium.webdriver.common.by import By
TIPS: Locating elements.
Step 3. The previous step provides multiple options for finding an element. You can either use CSS and XPath selectors or the inbuilt By.ID function. The selectors look like this:
element_by_id = driver.find_element(By.ID, "product_description").text
element_by_css = driver.find_element(By.CSS_SELECTOR, "#product_description").text
element_by_xpath = driver.find_element(By.XPATH, "//*[@id='product_description']").text
This is the output of the script. It shows the elements you’ve just scraped.

Results:
Congratulations, you’ve just found and extracted the content of an id using Selenium. Here’s the full script:
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html")
element_by_id = driver.find_element(By.ID, "product_description").text
element_by_css = driver.find_element(By.CSS_SELECTOR, "#product_description").text
element_by_xpath = driver.find_element(By.XPATH, "//div[@id='product_description']").text
driver.quit()
print (element_by_id)