In-Depth Look into Popular Web Scraping APIs
Web scraping is becoming more widespread but also increasingly challenging. To address the need for reliable infrastructure, proxy providers and other data collection companies have started releasing APIs that can scrape any website. They’re hardly a new phenomenon, but the number of such APIs has exploded during the last few years.
To give you some context, here’s their availability among major proxy providers:
2019: Oxylabs, Bright Data, Zyte
2022: Oxylabs, Bright Data, Zyte, Decodo (formerly Smartproxy), Rayobyte, Infatica, Shifter, GeoSurf, SOAX
This report takes an in-depth look into seven vendors of web scraping APIs. It compares their features, scraping performance, parsing capabilities, and cost effectiveness. We pay particular attention to three major website groups: search engines, e-commerce stores, and social media platforms.
Key Takeaways
- Web scraping APIs generally return raw HTML, but six out seven participants have parsers for specific websites. Google is the most popular target, then Amazon. Oxylabs offers a machine learning model for parsing most e-commerce stores.
- These APIs usually transfer data over an open connection. Most can take the form of proxies for easier integration, and three providers can send results to webhook or cloud storage.
- They’re relatively customizable, letting you select a location, device, and pass custom headers. Four APIs accept CSS selectors and three support browser interactions for dynamic scraping scenarios.
- In performance tests, few APIs found Google and Amazon a challenge, but some were several times faster than others. Social media (specifically, GraphQL) was tough for many. Overall, Oxylabs, Decodo, and Bright Data proved the most reliable.
- The same trio also had robust parsers. ScraperAPI and Rayobyte focused on returning crucial data points, and Shifter failed to localize results.
- Pricewise, the APIs can either charge the same for all features (Bright Data), have different prices by target group (Oxylabs, Decodo), or increase request price for premium functionality (ScraperAPI, Zyte). In the latter case, the rate can differ up to 75 times based on the website.
A Primer on Web Scraping APIs
If you’re unfamiliar with web scraping APIs, it makes sense to think of them as remote web scrapers. You interact with them by sending API requests with your target URLs and optional parameters like geolocation.
In the backend, the API selects appropriate proxies, applies headers, and launches headless browser instances if needed to open the target and extract its HTML. Having done its job, the API returns the data to you, either over open connection or using webhooks.
The more advanced (or rather specialized) APIs are able to parse the page to extract structured data points in JSON or other formats. They sometimes use parameterized syntax, where you simply enter a search query or Amazon’s product code (ASIN) instead of the full URL. The fancier systems involve complex tech like AI vision and pattern recognition models.
In any case, these APIs aim to deliver data without fail and nearly always base their pricing on successful requests. This makes expense tracking highly predictable and straightforward. But as we’ll see, some providers have managed to devise pricing models that are deceptively opaque.
Participants
We contacted a bunch of companies that offer web scraping APIs asking if they wanted to participate. After some back-and-forths, we ended up with seven participants. The list includes major names in the field, together with several well-established proxy providers that are moving into this category.
We informed the participants in advance that we’d be scraping Google, Amazon, and a social media network, and they voluntarily gave us access to relevant APIs.
|
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|
| APIs tested | Web Scraper API, SERP Scraper API, E-Commerce Scraper API | Web Unlocker, SERP API | Web Scraping API, SERP Scraping API, E-Commerce Scraping API | Zyte API | Scraping Robot | ScraperAPI | Web Scraping API, SERP API |
| Starting price | $99 | $3 (pay as you go), $500 (plan) | $50 | $0 (pay as you go), $25 (plan) | $0.0018/req | $49 | $44.95 |
Feature Overview
This part covers the integration methods, available API parameters, as well as ability to scrape and parse specific website groups.
Integration Methods
In theory, all web scraping APIs use the same basic structure: there’s an endpoint where you pass URLs you want to scrape with one or more parameters. In practice, the implementation can differ significantly. Here are the four main methods we’ve encountered:
| Oxylabs | Bright Data | Smartproxy | Zyte | Rayobyte | ScraperAPI | Shifter | |
|---|---|---|---|---|---|---|---|
| API (open connection) | ✅ | ❌ | ✅ | ✅ | ✅ | ✅ | ✅ |
| API (asynchronous) | ✅ | ✅ | ❌ | ❌ | ❌ | ✅ | ❌ |
| Proxy | ✅ | ✅ | ✅ | ❌ | ❌ | ✅ | ❌ |
| Library/SDK | ❌ | ❌ | ❌ | ✅ | ❌ | ✅ | ✅ |
Open connection means that you send requests to an API endpoint and wait for the response. This is the most popular approach, and most providers tailor their documentations around it. It has two variations: ScraperAPI and Shifter prefer the GET method, while others choose POST requests. The difference is mostly stylistic, as GET appends parameters to the URL, while POST sends them as a JSON payload.

Asynchronous delivery lets you send API calls with an ID and then fetch the results over webhook or other means whenever you want. It’s useful for scraping in bulk, and it gives the API more time to extract hard pages, as it’s no longer bound by timeout limits.

The majority of the APIs can also integrate as proxies. This method makes it easier to transition from regular proxy servers, as you can just plug in the API instead. Bright Data is the only participant that prefers the proxy method over others, as it treats its tools primarily as proxies. The API endpoint serves only for making batch requests.

We don’t consider SDKs a necessity. But they’re nice to have as an option.
HTML Scraping
General-purpose APIs have one endpoint that attempts to scrape any website you send its way. The caveat is that they don’t parse data, returning pages in raw HTML. All participants offer an API for general-purpose scraping:
| Oxylabs | Bright Data | Smartproxy | Zyte | Rayobyte | ScraperAPI | Shifter | |
|---|---|---|---|---|---|---|---|
| Relevant tool | Web Scraper API | Web Unlocker | Web Scraping API | Zyte API | Scraping Robot | ScraperAPI | Web Scraping API |
These APIs require very few parameters to function, usually only a token and URL. While convenient, this rarely suffices for all scenarios, so providers allow customizing various aspects of the request by passing additional parameters.
| Oxylabs | Bright Data | Smartproxy | Zyte | Rayobyte | Scraper API | Shifter | |
|---|---|---|---|---|---|---|---|
| Geolocation | All countries | All countries | All countries | 19 countries | ~130 countries | 34 countries | 10 countries |
| Residential proxies | ✅ | ✅ | ✅ | ✅ | ✅ | Paid option | Paid option |
| Device type | ✅ | ❌ | ✅ | ❌ | ✅ | ✅ | ✅ |
| Sessions | ✅ | ✅ | ❌ | ❌ | ✅ | ✅ | ✅ |
| Cookies | ✅ | ❌ | ❌ | ✅ | ✅ | ✅ | ✅ |
| Data input | ✅ | ❌ | ❌ | ✅ | ✅ | ✅ | ✅ |
One of the most frequent parameters is geolocation, which is determined by proxies. It’s pretty obvious which providers maintain their own proxy pools. Those that don’t support fewer countries and enable residential proxies as a paid parameter. (Shifter is an exception, but maybe it’s just stingy.) Zyte’s system automatically tries to match the location with the provided URL, so those 19 country options are for manual override.
The baseline for other parameters is similar: most APIs allow specifying a device type, creating sessions, and passing on cookies. One interesting parameter is what we call data input – it allows sending POST or PUT requests that the API forwards to the website. This is mostly useful for filling in forms.
Headless Scraping
Aside from overcoming website protection systems, headless scraping is another major pain point that pushes developers toward web scraping APIs. Knowing that, probably two thirds of the products we’ve overviewed use the slogan we manage headless browsers for you.
| Oxylabs | Bright Data | Smartproxy | Zyte | Rayobyte | ScraperAPI | Shifter | |
|---|---|---|---|---|---|---|---|
| JavaScript rendering | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Screenshots | ✅ | ❌ | ✅ | ✅ | ✅ | ❌ | ✅ |
| Browser actions | ❌ | ❌ | ❌ | ✅ | ✅ | ❌ | ✅ |
Unsurprisingly, JavaScript rendering is universally available. The basic implementation boils down to passing an additional parameter, usually called render, and you can add one more parameter to snap a screenshot. Bright Data handles JavaScript automatically, with no need for manual intervention.

Some providers take a step further and let you actually interact with the browser. For instance, Shifter has instructions to perform clicking and scrolling operations, while Rayobyte offers three parameters for page load events.
Zyte has gone the furthest in this regard: it’s built a whole TypeScript API that can do everything up to hovering on elements and entering individual symbols. The feature is available for enterprise clients, and you can write or access pre-written scripts via Zyte’s in-browser Visual Studio Code.
Specialized APIs
Most participants also offer specialized APIs for particular website groups. They bring several benefits over general-purpose scrapers.
First, you can be sure that the provider is able to scrape that website. General-purpose APIs have custom scrapers for popular targets; but because they’re abstracted behind one endpoint, there’s often guesswork (or trial and error) involved.
Second, specialized APIs bring a more structured approach to scraping. For example, instead of constructing the URL by hand, you can hit a Google Search endpoint with the query, location, and pagination as parameters.

Finally – and perhaps most importantly – specialized APIs have data parsers for returning structured data. We cover the parsing approaches further on.
| Oxylabs | Bright Data | Smartproxy | Zyte | Rayobyte | ScraperAPI | Shifter | |
|---|---|---|---|---|---|---|---|
| Search engine APIs | Google, Baidu, Bing, Yandex | Google, Bing, DuckDuckGo, Yandex | Google, Baidu, Bing, Yandex | ❌ | ❌ | Google, Bing, Yandex | |
| E-commerce APIs | Amazon, Walmart, eBay, Wayfair + 7 more | ❌ | Amazon, Idealo, Wayfair | ❌ | Amazon | ❌ | ❌ |
| Social media APIs | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
Search engines are generally the most popular candidates for custom scrapers, and they even constitute a separate category called SERP APIs. E-commerce APIs are rarer. Note the lack of dedicated social media scrapers. Faced by legal pressure, some providers refuse to mention certain platforms, let alone emphasize them.
Of course, Google and Amazon get the most attention. While the other targets are happy to get one API, these two can have up to ten! Their custom parameters aren’t only for convenience. In the case of Google, they also enable more precise targeting options which are crucial for local SEO.
| Oxylabs | Bright Data | Smartproxy | Rayobyte | Shifter | |
|---|---|---|---|---|---|
| APIs | Search, ads, hotels, images, autocomplete, search volume, trends | Search, maps, trends, reviews, hotels, reverse image | Search, ads, hotels, images, autocomplete, trends | Search | Search, maps, autocomplete, scholar, product, reverse image, jobs, events, Google Play, trends |
| Search type (tbm) | ✅ | ✅ | ✅ | ❌ | ✅ |
| Device type | ✅ | ✅ | ✅ | ❌ | ✅ |
| Location selection | City-level | City-level | City-level | Country-level | City-level |
| Localization | Domain, language | Domain, language | Domain, language | Domain, language | Domain, language |
| Pagination | Start, number of pages | Start, number of pages | Start, number of pages | Number of pages | Start, number of pages |
| Oxylabs | Smartproxy | Rayobyte | |
|---|---|---|---|
| APIs | Bestsellers, pricing, product, QA, reviews, search, sellers | Product, pricing, reviews, QA, search, sellers | Product |
| Device type | ✅ | ✅ | ❌ |
| Domain | ✅ | ✅ | ❌ |
| Delivery location | ✅ | ✅ | ❌ |
| Pagination | Start, number of pages | Start, number of pages | ❌ |
Data Parsing
As a rule, the ability to parse data comes with specialized APIs. But there are exceptions. Some providers expose selectors for building a parser manually. ScraperAPI takes yet another approach – it can parse specific Google and Amazon properties by adding a parameter to the general-purpose API:

Overall, here are the data parsing capabilities of each participant:
| Oxylabs | Bright Data | Smartproxy | Zyte | Rayobyte | ScraperAPI | Shifter | |
|---|---|---|---|---|---|---|---|
| Manual parsing | ❌ | ❌ | ❌ | CSS selectors | CSS, XPath selectors | ❌ | CSS selectors |
| Search engine parsers | Google, Bing, Yandex, DuckDuckGo | ❌ | Google, Bing, Yandex | ||||
| E-commerce parsers | Amazon, Walmart, eBay, Wayfair, Target, Etsy, AI parsing | ❌ | Amazon | ❌ | Amazon | Amazon | ❌ |
Three participants allow creating extraction rules with selectors. We’re doubtful about this feature, as you still have to build a parser manually and then decouple it from the code if you quit using the tool.
If a provider has one pre-built parser, it’s pretty safe to bet on Google. Bright Data and Shifter are also good choices for extracting structured data from minor search engines.
Fewer participants can parse e-commerce stores – at least in the context of the APIs we tested. Oxylabs alone supports targets other than Amazon. In fact, the provider has developed a machine learning model that attempts to structure any product page. It seems like a valuable feature, so we expect more companies to follow suit.
Once again, Google and Amazon are the focus. For the former, the baseline and most valuable property is its Search Engine Results Page (SERP). Amazon parsers, on the other hand, try to cover at least search and product pages:
| Oxylabs | Bright Data | Smartproxy | Rayobyte | ScraperAPI | Shifter | |
|---|---|---|---|---|---|---|
| Data formats | ||||||
| JSON, CSV | JSON | JSON | JSON | JSON | JSON | |
| Parsable elements | ||||||
| SERP | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Search types (tbms) | Images, news, shopping | Images, news, shopping, videos, maps, hotels | Shopping | ❌ | Shopping | Images, news, shopping, videos, maps |
| Other | Ads, autocomplete, reverse image, monthly search volume, trends | Reverse image, trends, reviews | Ads, autocomplete, trends | ❌ | ❌ | Autocomplete, reverse image, scholar, Play, trends |
| Oxylabs | Smartproxy | Rayobyte | ScraperAPI | |
|---|---|---|---|---|
| Data formats | ||||
| JSON | JSON | JSON | JSON | |
| Parsable elements | ||||
| Search | ✅ | ✅ | ❌ | ✅ |
| Product | ✅ | ✅ | ✅ | ✅ |
| Reviews | ✅ | ✅ | ❌ | ✅ |
| Others | Bestsellers, ASIN prices, QA, seller info | ASIN prices, QA | Offer listings | |
Performance Benchmarks
We tested the APIs using a custom Python script. It was written using Asyncio and AIOHTTP libraries to send asynchronous requests with a timeout of 150 seconds.
We took Google, Amazon, and a photo-focused social media platform as our targets and devised several scenarios around them.
| Target | Requests | Purpose |
|---|---|---|
| Google search engine pages | 1 per minute for a week, 10,800 in total | Test the success rate, speed, and stability of an API |
| Test the ability to scrape Google | ||
| Amazon product URLs | 1,000 | Test the ability to scrape Amazon |
| Profiles of a photo-focused social media platform | 500 to a graphql endpoint | Test the ability to scrape protected social media websites |
| 500 fully-rendered requests | Test the success rate and speed of headless scraping |
Here’s how the APIs performed:
Our main target was Google. We scraped it twice: one time to extract raw HTML results, and the second time with data parsing enabled.
| Oxylabs | Bright Data | Smartproxy | Zyte | Rayobyte | ScraperAPI | Shifter | |
|---|---|---|---|---|---|---|---|
| Success rate | 100% | 98.42% | 100% | 99.47% | 100% | 94.10% | 81.76% |
| Avg. response time | 6.04 | 4.62 | 6.09 | 4.72 | 6.53 | 12.58 | 1.67 |
Most APIs did well. Shifter’s Google API only returns parsed data, so we used its general-purpose scraper for the first test. It obviously wasn’t equipped to handle Google – every fifth request returned a 429 detection error. The specialized API did better, though its speed fell significantly.
| Oxylabs | Bright Data | Smartproxy | Zyte | Rayobyte | ScraperAPI | Shifter | |
|---|---|---|---|---|---|---|---|
| Success rate | 99.90% | 99.71% | 99.85% | – | 99.93% | 96.88% | 96.65% |
| Avg. response time | 6.15 | 6.03 | 6.04 | – | 10.03 | 13.24 | 10.08 |
Using a data parser had little impact on the response time. Rayobyte was an exception – for some reason, it returned results over three seconds slower in JSON.
We only ran one test on Amazon with data parsing enabled where possible.
| Oxylabs | Bright Data | Smartproxy | Zyte | Rayobyte | ScraperAPI | Shifter | |
|---|---|---|---|---|---|---|---|
| Success rate | 100% | 98.42% | 100% | 85.50% | 95.60% | 95.80% | 98.80% |
| Avg. response time | 4.69 | 4.31 | 4.66 | 4.51 | 20.70 | 9.69 | 5.35 |
Bright Data, Oxylabs, and Smartproxy once again displayed excellent results. Shifter was close behind, ScraperAPI basically repeated its Google performance, and Zyte returned quite a few 520 errors. Rayobyte’s response time was slow; we found out that the latter provider uses datacenter IPs for Amazon by default, and so the API had to retry requests multiple times.
We scraped the photo-focused social media platform two times: one targeting its GraphQL endpoint, the other fully rendering profile pages.
| Oxylabs | Bright Data | Smartproxy | Zyte | Rayobyte | ScraperAPI* | Shifter | |
|---|---|---|---|---|---|---|---|
| Success rate | 100% | 73.40% | 100% | 98.40% | 80% | 24.80% | 54.80% |
| Avg. response time | 17.89 | 3.71 | 8.95 | 2.59 | 4.52 | 8.08 | 1.77 |
The GraphQL endpoint proved to be a much more serious challenge than either Google or Amazon. Shifter had a hard time, even after we enabled rendering. It seems like its scraper is configured to fail fast, whereas others try to retry requests. ScraperAPI really struggled – we tried toggling premium proxies and the headless mode, but nothing helped much. In this context, Zyte stood out.
| Oxylabs | Bright Data | Smartproxy | Zyte | Rayobyte | ScraperAPI* | Shifter | |
|---|---|---|---|---|---|---|---|
| Success rate | 100% | 100% | 100% | 94.00% | 98.60% | 98.20% | 62.40% |
| Avg. response time | 28.88 | 4.10 | 29.09 | 28.14 | 23.05 | 16.05 | 4.42 |
The headless test was more forgiving. Bright Data won hands down, with a perfect success rate and an amazing response time. To be fair, its API toggles rendering automatically, so maybe headless browsers weren’t used. The results are impressive nonetheless. Only Shifter was similarly fast, but its scraper errored out on every third request. Not great for a tool that advertises a 100% success rate.
The other providers showed more realistic response times with the headless mode enabled. This was ScraperAPI’s best result from the three targets, which is somewhat ironic considering the provider blocks it by default. Oxylabs and Smartproxy maintained their success rate but had to sacrifice some speed to do so.
Concurrency
Even if an API returns data lightning fast, it will often have artificial limitations imposed by the provider. So, how fast can you theoretically make requests?
| Oxylabs | Bright Data | Smartproxy | Zyte | Rayobyte | ScraperAPI | Shifter | |
|---|---|---|---|---|---|---|---|
| Concurrency | 5 req/s to unlimited | Unlimited | Unspecified | 2 req/s | 100 req/min | 200-400 threads | Unspecified |
It depends. For example, Bright Data doesn’t have explicit limits on the number of parallel requests you can make. Coupled with its fast response times, the API can scale very well. The same goes for Decodo and Oxylabs where the limits are lenient and become even more so with larger pricing plans.
On the other hand, Rayobyte allows making 100 requests per minute by default, which translates to 1.66 per second. If you scrape Amazon or render JavaScript, you’ll reach the ceiling relatively quickly. The same goes for Zyte. Of course, both providers allow lifting the limits, but this applies mainly to customers with enterprise-level needs.
Parsing Capabilities
We were also interested to see how well the APIs are able to parse pages, and how much of the page they can return. This was a small-scale qualitative test, so take it with a grain of salt. We took four kinds of pages and analyzed them by hand:
- Localized Google search desktop query,
- Localized Google search mobile query,
- Google Shopping query,
- Amazon product pages.
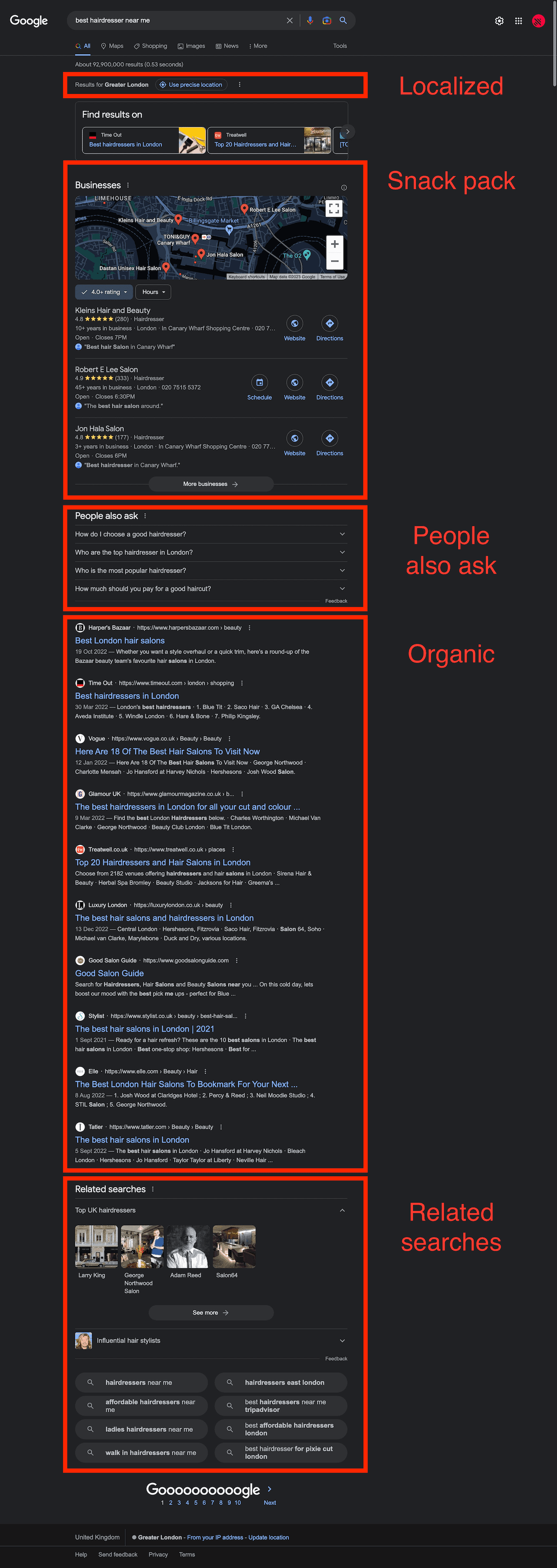
For the first test, we used the query best hairdresser near me (reference page) with the location set to London, UK.
| Oxylabs | Bright Data | Smartproxy | Rayobyte | ScraperAPI | Shifter | |
|---|---|---|---|---|---|---|
| Localized? | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
| Organic | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Snack pack | ✅ | ✅ | ✅ | ❌ | ❌ | ✅ |
| Map | ❌ | ✅ | ❌ | ❌ | ❌ | ❌ |
| Related searches | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| People also ask | ✅ | ✅ | ✅ | ✅ | ❌ | ✅ |
The participants used two kinds of approaches: ScraperAPI and Rayobyte returned only the crucial information, whereas the others tried to parse all elements of the SERP. (Bright Data even returned a screenshot of the map!) Rayobyte’s results confirm our tests from early 2022, so we can assume that its parser works the same for most queries.
For some reason, Shifter’s location parameter didn’t work, and so the API wasn’t able to return local results.
The mobile query used all the same parameters, device being the only exception.
| Oxylabs | Bright Data | Smartproxy | Rayobyte | ScraperAPI | Shifter | |
|---|---|---|---|---|---|---|
| Localized? | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
| Organic | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Snack pack | ✅ | ✅ | ✅ | ❌ | ❌ | ✅ |
| Map | ❌ | ✅ | ❌ | ❌ | ❌ | ❌ |
| Related searches | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| People also ask | ✅ | ✅ | ✅ | ✅ | ❌ | ✅ |
Bright Data, Oxylabs, and Smartproxy had no issues returning full and accurate results. Shifter’s mobile parser regressed to the main page elements, and it once again couldn’t return local data. ScraperAPI failed to scrape anything, and Rayobyte’s parser doesn’t have a parameter for selecting device type.
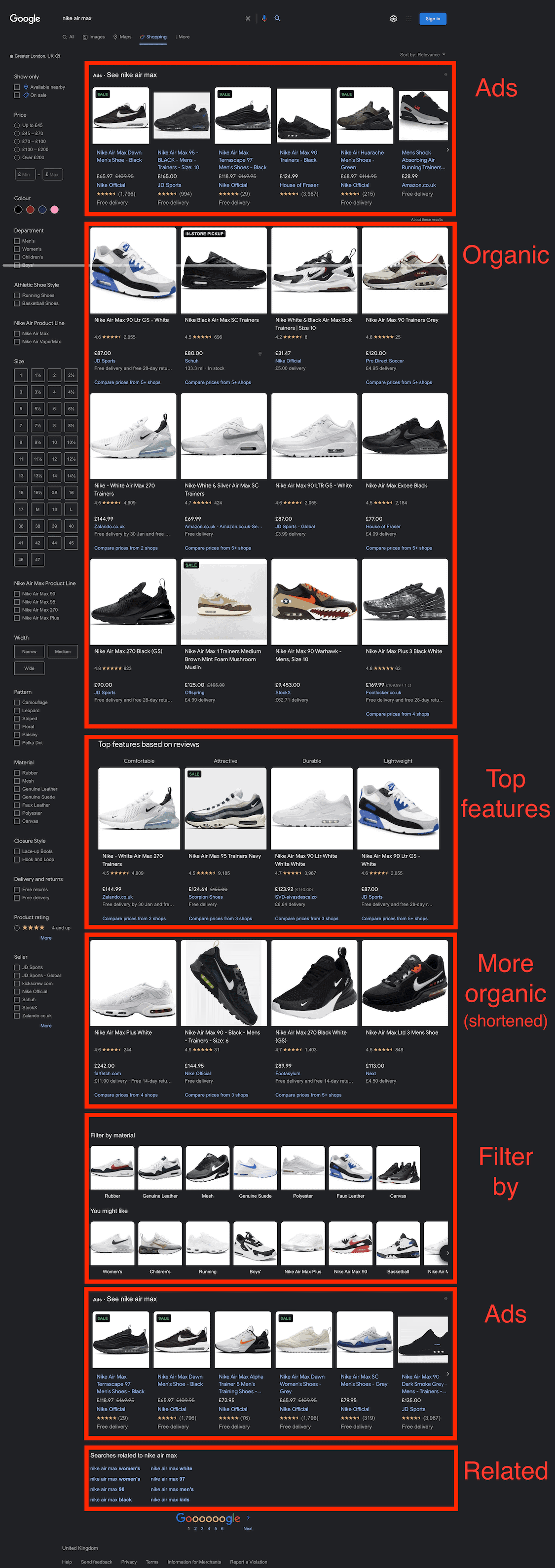
We used the query Nike Air Max (reference page) targeting Google’s Shopping search type (tbm) with the location set to London, UK.
| Oxylabs | Bright Data | Smartproxy | ScraperAPI | Shifter | |
|---|---|---|---|---|---|
| Localized? | ✅ | ❌ | ✅ | ✅ | ❌ |
| Search filters | ✅ | ❌ | ✅ | ❌ | ❌ |
| Ads | Failed to return | Failed to return | Failed to return | ✅ | ✅ |
| Item | Title, URL, thumbnail, ID | Title, URL, thumbnail, ID | Title, URL, thumbnail, ID | Title, URL, thumbnail, ID | Title, URL, thumbnail |
| Pricing | Parsed price, currency | Price with currency | Parsed price, currency | Price with currency, parsed price | Price with currency, parsed price |
| Merchant | Name, URL | Name | Name, URL | Name | Name |
| Delivery | ❌ | ✅ | ✅ | ✅ | ❌ |
| Evaluation | Review count | Rating, review count | Review count | Rating | Rating, review count |
| Other | Price comparison | Filter by material, you might like, related searches, price comparison |
ScraperAPI returned the most complete result, including related searches and the you might like block. It was also one of the two providers to retrieve ad results (the others had this field empty). Oxylabs and Smartproxy were the only providers with search filters, while Bright Data and Shifter failed to localize the page for this particular request.
We targeted multiple product pages from different categories, such as art supplies, kitchenware, and electronics (reference page).
| Oxylabs | Smartproxy | Rayobyte | ScraperAPI | |
|---|---|---|---|---|
| Breadcrumbs | ✅ | ✅ | ✅ | ✅ |
| Item | Title, ASIN, description, bullet points, product details, model # | Title, ASIN, description, bullet points, product details, model # | Title, ASIN, description, bullet points, product details | Title, description, bullet points, product details, model # |
| Images | ✅ | ✅ | ✅ | ✅ |
| Item variations | ✅ | ✅ | ❌ | ✅ |
| Pricing | Price, currency, discounts | Price, currency, discounts | Price, currency | Price (with currency) |
| Merchant | Buy box, other offers | Buy box, other offers | Other offers | Buy box, other offers |
| Availability | Stock, max quantity, first available | Stock, max quantity, first available | Stock, first available | Stock, first available |
| Bestsellers rank | ✅ | ✅ | ✅ | ✅ |
| Delivery | Price, shipping details | Price, shipping details | ❌ | Price |
| Evaluation | Review count, star average, # of questions, star distribution, top review | Review count, star average, # of questions, star distribution, top review | Review count, star average, # of questions | Review count, star average, # of questions |
| Warranty | ✅ | ✅ | ❌ | ❌ |
All four APIs were able to parse most page elements. Oxylabs and Smartproxy had the most complete results, as their .json files also included discounts, delivery and warranty information, which the other two APIs lacked.
Rayobyte’s parser was the least informative: its output missed item variations, delivery and warranty information. The provider chose to exclude the buy box data, likely because it frequently changes, opting for a URL to available sellers instead. We also encountered a few formatting errors, though nothing critical.
Cost Effectiveness
In this final section, we explore the pricing models of web scraping APIs, factors that influence their price, and how much these scrapers cost in different scenarios (for example, getting the HTML of unprotected websites vs scraping interactive targets).
Pricing Models
Almost without exception, web scraping APIs base their pricing around successful requests. This makes counting expenses simple: if a request fails, you don’t pay. You should also be able to easily compare the costs of several providers by looking at their CPMs (price per 1,000 requests).
| Oxylabs | Bright Data | Smartproxy | Zyte | Rayobyte | ScraperAPI | Shifter | |
|---|---|---|---|---|---|---|---|
| Pricing model | Subscription | Pay as you go, subscription | Subscription | Pay as you go, subscription | Pay as you go | Subscription | Subscription |
| Structure | Successful requests | Successful requests | Successful requests | Successful requests | Successful requests | Successful requests | Successful requests |
| Starting price | $99 | $3 (pay as you go), $500 (plan) | $50 | $0 (pay as you go), $25 (plan) | $0.0018/request | $49 | $44 |
| Trial | 5,000 req for a week | 7 days for companies | 3,000 req for 3 days | $5 free credit | 5,000 free per month | 5,000 credits for a week | Money-back guarantee |
In our case, there were no exceptions. All providers charge for 200 (and usually 404) response codes, excluding hidden CAPTCHAs and other failed responses. Some providers allow paying as you go, but the dominant model is still monthly subscription. Zyte’s approach is pretty interesting: you set a monthly limit and pay half of the sum in advance each month.
We’re used to proxy networks which rarely have trials due to abuse, so it’s nice to see that you can get one with almost any provider. The standard seems to be 5,000 requests, which should be enough to properly test the scraper. Rayobyte goes a step further and actually renews the trial every month, effectively offering a free plan.
Calculating Request Price
Despite their simple pricing model, some web scraping APIs make counting a request’s price a challenge. They introduce price modifiers based on the target, JavaScript rendering, residential proxies, and more. As a result, the cost for scraping two websites – with the same plan – can differ up to 75 times!
| Oxylabs | Bright Data | Smartproxy | Zyte | Rayobyte | ScraperAPI | Shifter | |
|---|---|---|---|---|---|---|---|
| Price modifiers | Search engines, e-commerce websites | – | Search engines, e-commerce websites | Target, JS rendering, premium proxies, screenshots, browser actions | – | Premium, super premium proxies, premium targets, JS rendering | Premium proxies, JS rendering, search engines |
| Max price difference | x2-3 | x1 | x1.5-3 | Custom | x1 | x75 | x25 |
ScraperAPI is the most obvious example of this. It has an elaborate structure that combines three tiers of proxy networks (regular, premium residential, super premium) and JavaScript rendering. For example, enabling residential proxies costs 10 credits, combining them with headless scraping – 25. There’re also different rates for websites like Google (25 credits), Amazon (5 credits), and social media (30 credits).
Providers like Oxylabs and Decodo differentiate the cost by website group. Compared to the general-purpose API, their search engine scrapers cost 2-3 times more, and e-commerce scrapers are roughly twice as expensive. Shifter uses the same approach for search engines, while its regular scraper takes after ScraperAPI.
Bright Data and Rayobyte somehow keep their price the same whether you use their custom scrapers or render JavaScript. This is great for simplicity and scraping hard targets but may not be as efficient for unprotected websites.
Zyte deserves a separate mention. It calculates the price per request dynamically for each website, taking into account its difficulty, whether you rendered JavaScript, whether you made a screenshot, and if you ran browser actions. The latter takes into account CPU and network consumption. It’s pointless to approximate expenses in advance – or even expect them to remain the same, as Zyte adjusts the cost when it or target websites make changes.

Cost in Different Scenarios
So, how much does it actually cost to scrape websites with the APIs? We calculated the rate per 1,000 requests at different price points.
Some clarification: Basic scenario refers to an unprotected website that can be scraped without premium proxies. In other cases, we took the cheapest configuration that could scrape the target consistently.
Cost per 1,000 requests when paying $50 for the service.
| Oxylabs | Bright Data | Smartproxy | Zyte | Rayobyte | ScraperAPI | Shifter | |
|---|---|---|---|---|---|---|---|
| Basic websites | – | $3 | $2 | $0.50 | $1.80 | $0.49 | $0.45 |
| – | $3 | $3.85 | ~$1.50 | $1.80 | $12.25 | $9.00 | |
| Amazon | – | $3 | $3.35 | ~$1.20 | $1.80 | $2.45 | $2.25 |
| Social media | – | $3 | $2 | ~$0.50 | $1.80 | $14.90 | $11.25 |
| Social media (rendered) | – | $3 | $2 | ~$23 | $1.80 | $19.60 | $11.25 |
Cost per 1,000 requests when paying $100 for the service.
| Oxylabs | Bright Data | Smartproxy | Zyte | Rayobyte | ScraperAPI | Shifter | |
|---|---|---|---|---|---|---|---|
| Basic websites | $1.30 | $3 | $1.00 | ~$0.40 | $1.80 | $0.15 | $0.45 |
| $3.40 | $3 | $2.86 | ~$1.30 | $1.80 | $3.73 | $9.00 | |
| Amazon | $3.00 | $3 | $2.00 | ~$1.00 | $1.80 | $0.75 | $2.25 |
| Social media (graphQL) | $1.30 | $3 | $1.00 | ~$0.40 | $1.80 | $4.50 | $11.25 |
| Social media (rendered) | $1.30 | $3 | $1.00 | ~$20 | $1.80 | $6.00 | $11.25 |
Cost per 1,000 requests when paying $250 for the service.
| Oxylabs | Bright Data | Smartproxy | Zyte | Rayobyte | ScraperAPI | Shifter | |
|---|---|---|---|---|---|---|---|
| Basic websites | $1.30 | $3 | $0.90 | ~$0.34 | $1.80 | $0.15 | $0.135 |
| $3.40 | $3 | $2.50 | ~$1.1 | $1.80 | $3.73 | $7.50 | |
| Amazon | $3.00 | $3 | $1.67 | ~$0.83 | $1.80 | $0.75 | $0.68 |
| Social media (graphQL) | $1.30 | $3 | $0.90 | ~$0.34 | $1.80 | $4.50 | $3.38 |
| Social media (rendered) | $1.30 | $3 | $0.90 | ~$17 | $1.80 | $6.00 | $3.38 |
Cost per 1,000 requests when paying $500 for the service.
| Oxylabs | Bright Data | Smartproxy | Zyte | Rayobyte | ScraperAPI | Shifter | |
|---|---|---|---|---|---|---|---|
| Basic websites | $1.00 | $2.55 | $0.80 | ~$0.30 | $1.80 | $0.10 | $0.09 |
| $2.50 | $2.55 | $2.00 | ~$0.93 | $1.80 | $2.50 | $4.50 | |
| Amazon | $2.00 | $2.55 | $1.50 | ~$0.71 | $1.80 | $0.50 | $0.45 |
| Social media (graphQL) | $1.00 | $2.55 | $0.80 | ~$0.30 | $1.80 | $3 | $2.25 |
| Social media (rendered) | $1.00 | $2.55 | $0.80 | ~14.70 | $1.80 | $4 | $2.25 |
Cost per 1,000 requests when paying $1,000 for the service.
| Oxylabs | Bright Data | Smartproxy | Zyte | Rayobyte | ScraperAPI | Shifter | |
|---|---|---|---|---|---|---|---|
| Basic websites | $0.60 | $2.40 | $0.60 | ~$0.24 | Custom | $0.07 | Custom |
| $1.90 | $2.40 | $1.80 | ~$0.76 | Custom | $1.75 | Custom | |
| Amazon | $1.50 | $2.40 | $1.40 | ~$0.58 | Custom | $0.45 | Custom |
| Social media (graphQL) | $0.60 | $2.40 | $0.60 | ~$0.24 | Custom | $2.1 | Custom |
| Social media (rendered) | $0.60 | $2.40 | $0.60 | $12 | Custom | $2.8 | Custom |
The tables do a great job at showing how price modifiers work in practice. ScraperAPI, Shifter, and Zyte all look cheap at first – and they sure are, as long as you stick to easy targets. But they very quickly balloon in price once premium proxies and especially headless browsers get involved.
The other providers are more predictable: they’re expensive for scraping unprotected websites, offer competitive specialized APIs, and make a lot of sense if you need JavaScript. Bright Data’s enterprise-oriented pricing doesn’t scale much within the range we looked at, while Rayobyte is cheap at first (basic websites excluded) but keeps the same rate for way too long.
Finally, it makes no sense to buy <$50 plans. At $100, ScraperAPI cuts its rate nearly thrice, and Decodo becomes half as expensive.
Conclusion
The landscape of web scraping APIs is surprisingly varied. You can buy a scraper with limited features for extracting HTML pages on a small budget, or you can invest more and get structured data from anywhere in the world. Some APIs can integrate as proxies to keep the transition simple, while others let you build custom parsers and even script browser interactions.
We hope that our research helped you to get acquainted with this category of web scrapers, and that you’re better set to make a buying decision if you were looking to get one.

{kind=link}
{kind=link}
{kind=link}