How to Get Text Using LXML
You’ll need to use an XPath selector to get data. Refer to the XPath Tutorial if you need a refresher.
Step 1. Install LXML using pip.
pip install lxml
from lxml import etree
import requests
Example 1
Step 2. Let’s start by inspecting the source code of your target page. We’ll be using our The Best Residential Proxy Providers page in this example. You can find providers’ names in divs with the brand class.
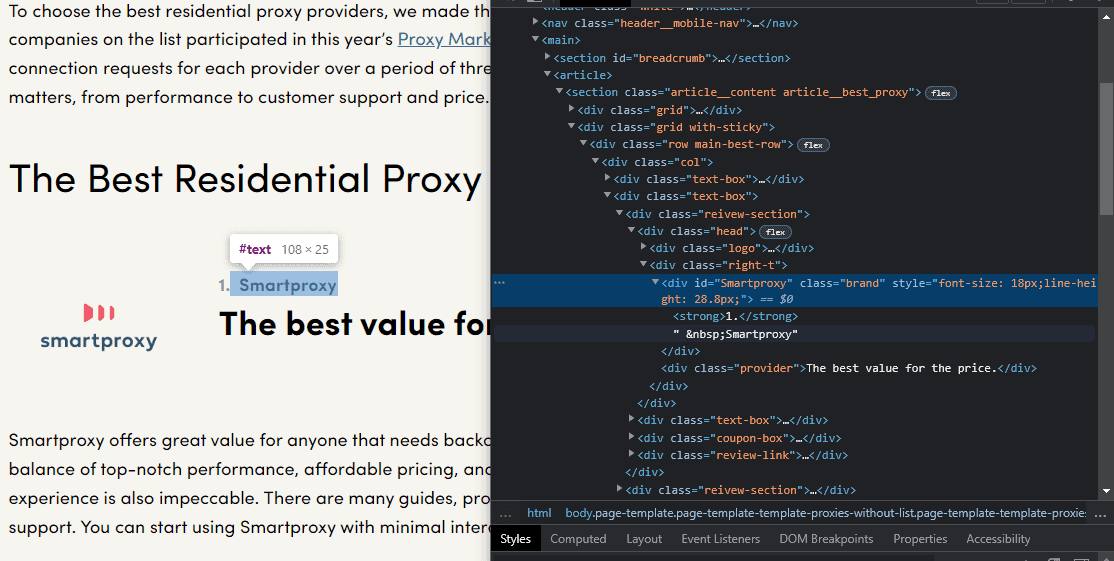
Step 3. Then, make an HTTP request and assign the response to the r variable to scrape the site.
r=requests.get("https://proxyway.com/best/residential-proxies")
Step 4. Parse the HTML response content using etree.HTML() parser provided by LXML.
tree = etree.HTML(r.text)
Step 5. Select the div elements containing the class brand and get the text element.
divs = tree.xpath(".//div[@class='brand']/text()")
Let’s have a closer look at the code:
- .//div – select all divs within the HTML document.
- .//div[@class=’brand’] – select all divs that have a class of brand.
- /text() – get the text that is contained in the div.
NOTE: The result is a list of LXML elements.
Step 6. Let’s print out the divs list. You can see that it also contains blank spaces and non-breaking spaces (\xa0 elements) that we don’t need:

You can clean up the results and assign them to a new brand_names list:
brand_names = []
for div in divs:
if len(div.strip()) > 0:
brand_names.append(div.strip())
This is the output of the script. It shows provider names you’ve just scraped.

Results: Congratulations, you’ve extracted the content. Here’s the full script:
from lxml import etree
import requests
r=requests.get("https://proxyway.com/best/residential-proxies")
tree = etree.HTML(r.text)
divs = tree.xpath(".//div[@class='brand']/text()")
brand_names = []
for div in divs:
if len(div.strip()) > 0:
brand_names.append(div.strip())
#print (brand_names)
Example 2
r=requests.get("https://books.toscrape.com")
Step 4. Parse the HTML response content using etree.HTML() parser provided by LXML.
tree = etree.HTML(r.text)
Step 5. Now let’s get the book title by inspecting the code. The title can be found within an h1 tag in a div with a product_main class:

The XPath should look like this:
title = tree.xpath("//div[@class='col-sm-6 product_main']/h1/text()”)[0]
NOTE: However, that won’t work as there is another class present – col-sm-6. So, the XPath selector won’t find this exact div.
Step 6. Let’s specify both classes so that the XPath work.
title = tree.xpath("//div[@class='col-sm-6 product_main']/h1/text()”)[0]
You can also use the contains() method as an alternative:
title = tree.xpath("//div[contains(@class,'product_main')]/h1/text()")[0]
print (f'Title: {title}')
Let’s have a closer look at the code:
- (@class) – selects all classes from the document.
- //div([contains(@class,’product_main’]) – selects the div that contains a product_main class.
- /h1 – the title text is not in the div itself but in its <h1> child element.
- /h1/text() – gets the text from within the <h1> tags.
- [0] – since tree.xpath() method returns a list and we want text, we can simply grab the first element of the said list.
Step 6. Now let’s get the book description. It can be found in a <p> tag without any descriptive attributes below the div, which contains its heading.

One way to get the description text and avoid selecting any other <p> elements that aren’t relevant look like this:
description = tree.xpath("//div[@id='product_description']/following-sibling::p/text()")[0]
print (f'Description: {description}')
- //div[@id=’product_description’] – we select the div with an id of product_description so that we wouldn’t select the wrong element.
- /following-sibling::p – selecting the next <p> sibling of the div we have selected before. You can get more information about Xpath Axes here.
- /text() – getting the text within the <p> tags.

Results: Congratulations, you’ve extracted the book name and description. Here’s the full script:
from lxml import etree
import requests
r=requests.get('https://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html')
tree = etree.HTML(r.text)
title = tree.xpath("//div[contains(@class,'product_main')]/h1/text()")[0]
print (f'Title: {title}')
description = tree.xpath("//div[@id='product_description']/following-sibling::p/text()")[0]
print (f'Description: {description}')