Search APIs in 2026: Overview & Benchmarks
The rising tide of AI has lifted all web scraping boats, but retrieval-augmented generation and AI agents have made SERP APIs (lately called Search APIs) in particularly high demand. Well-financed and ambitious companies are reshaping what was an established category of web scraping tools.
Our report aims to capture this shift: we explore the status quo in early 2026, compare the three types of search APIs, and benchmark 15 providers to see how they perform.
Key Findings
- The market has segmented into full search APIs used for human-oriented purposes, indices aimed at serving AI, and fast APIs that bridge the first two categories.
- The main difference between fast APIs and indices is that the former return real-time data but rarely extract the pages found through search.
- Google has been working hard to stop web scraping ever since January 2025, constantly changing access mechanisms and even taking scraper companies to court.
- In our speed test, the fastest indices like Exa and Perplexity fetched results in under 0.4 seconds with little variance. Oxylabs and Serper were the fastest real-time APIs, reaching a median response time of 0.6-0.7 seconds.
- Real-time APIs cost less and scale better, but they require other tools to carry out search and page extraction. Indices converge at around $5 per 1,000 requests.
SERP Scraping Before 2024
Before LLMs, search engine scraping had relatively defined problem areas. It serviced SEO agencies and tools, ad verifiers, brand protection companies, and other businesses that relied on search data.
The aim of SERP APIs was to reliably fetch as much of the search engine page as they could. At first they included only organic results, ads, people-also-ask boxes, and related queries. With time, their reach expanded to knowledge graphs, snack maps, local results, shopping boxes, search verticals (like Hotels), and all the other doodads that grew to populate the search page.

We always found it curious that it was only SERP APIs which formed their own subset of web scraping, with brands dedicated exclusively to search engines. Their main target was, of course, Google, followed by Bing, Yandex, and sometimes the search pages of e-commerce websites like Amazon.
In any case, consumers of SERP data were looking to understand and manipulate how search engines interacted with humans, within the boundaries of the platform they worked with.
Post-AI Search APIs
By 2023, ChatGPT had been available for a year. It became clear that training datasets weren’t enough: to become truly relevant, chatbots needed a way to access the world’s knowledge as it was generated. Retrieval-augmented generation (RAG) took off to free language models from the constraint of knowledge cut-off dates.
This gave a huge new impetus for accessing search engines as both the source of knowledge and the guide for reaching it. On the promise of making search more accessible for AI, LinkUp raised $13M, Tavily got $25M, Exa received $85M, Parallel secured $100M, while You pivoted from a consumer search engine with a similarly impressive $100M investment round.
Web search for AI has very different requirements compared to human consumers:
- For one, data retrieval needs to be fast – way faster than the 4+ seconds of a typical SERP API response. This has prompted companies to create their own pre-scraped indices: very expensive but made possible by venture capital funding.
- Because an index isn’t real-time and thus unfaithful to Google, APIs have to re-rank results based on their own criteria. For example, Tavily assigns each page it surfaces with a relevance score.
- Furthermore, language models aren’t content with just the search results page – they also need to know the contents of the results. The response can include the full output, highlights that fit context windows, or straight up LLM-written answers to the query.
- And finally, AI doesn’t need the full SERP. Ads, widgets, and mobile layouts serve little use in a knowledge lookup, except for certain edge case scenarios.
In 2025, the Silicon Valley hivemind converged around a new use case – AI agents. It shifted SERP APIs even further away from their conceptual roots. Their main purpose became to rebuild web search for a new consumer, which was no longer human but rather AI. In other words, companies stopped wanting to work within a search engine – instead, they hoped to replace existing search interfaces with their own (not without consequences, but more on that later).
While search APIs were making headlines, another product category quietly sprung up, the so-called fast or light SERP APIs. They sacrifice most unnecessary page elements in exchange for pure speed, often reaching less than a second per response. The original and most successful fast SERP API has been Serper; established providers like Oxylabs, Bright Data, and SerpApi have since introduced fast versions of their own.
Google’s Response
Google has always been one of the main web scraping targets, but the search giant seemingly didn’t pay it much mind. Sure, datacenter proxy servers stopped working well at some point, and badly configured spiders would receive their share of CAPTCHAs. But before 2025, the platform never posed a serious challenge like LinkedIn or some e-commerce stores.
How come? Blocking scrapers while being the largest web scraper doesn’t lead to great optics. But in a more practical sense, prior business models never seriously threatened Google’s ad empire. On the other hand, AI agents don’t care about viewing, and they certainly don’t care about buying ads. By the time Bright Data brought together a bunch of search APIs to talk about upending Google in November 2025, the straw had already broken the camel’s back.
In mid-January 2025, Google disrupted every single web scraper (and a good deal of accessibility tools) by implementing SearchGuard – a JavaScript-dependent bot protection system. Though presenting few changes to the regular user, this move increased the scraping latency and costs by an order of magnitude. Several days later, things more or less stabilized, but a die had been cast.
Google’s second hit came in September when it removed the &num=100 parameter. The omission aimed explicitly at web scrapers, primarily AI companies. Among those affected the most were various SEO tools like Ahrefs, which relied on the extended SERP for visibility into rankings and keywords. Half a year in, their functionality remains more limited than before the change.
Alongside these seismic events, Google relentlessly works to make scraping the search engine harder. It hired dedicated anti-bot engineers to persistently break unblocking strategies, page parsing schemas, and stitched-together &num=100 substitutes.
Discontent with engineering efforts alone, Google brought the matter to court, suing SerpApi in December 2025. The case hinged on two arguments: circumvention of Google’s SearchGuard technology, incurring a deadweight loss; and unauthorized scraping of licensed content like the Knowledge Panel, which allegedly infringed on the Digital Millennium Copyright Act. The claimant seeks $200-$2,500 for each scraped page, which everyone knows is impossible to satisfy.
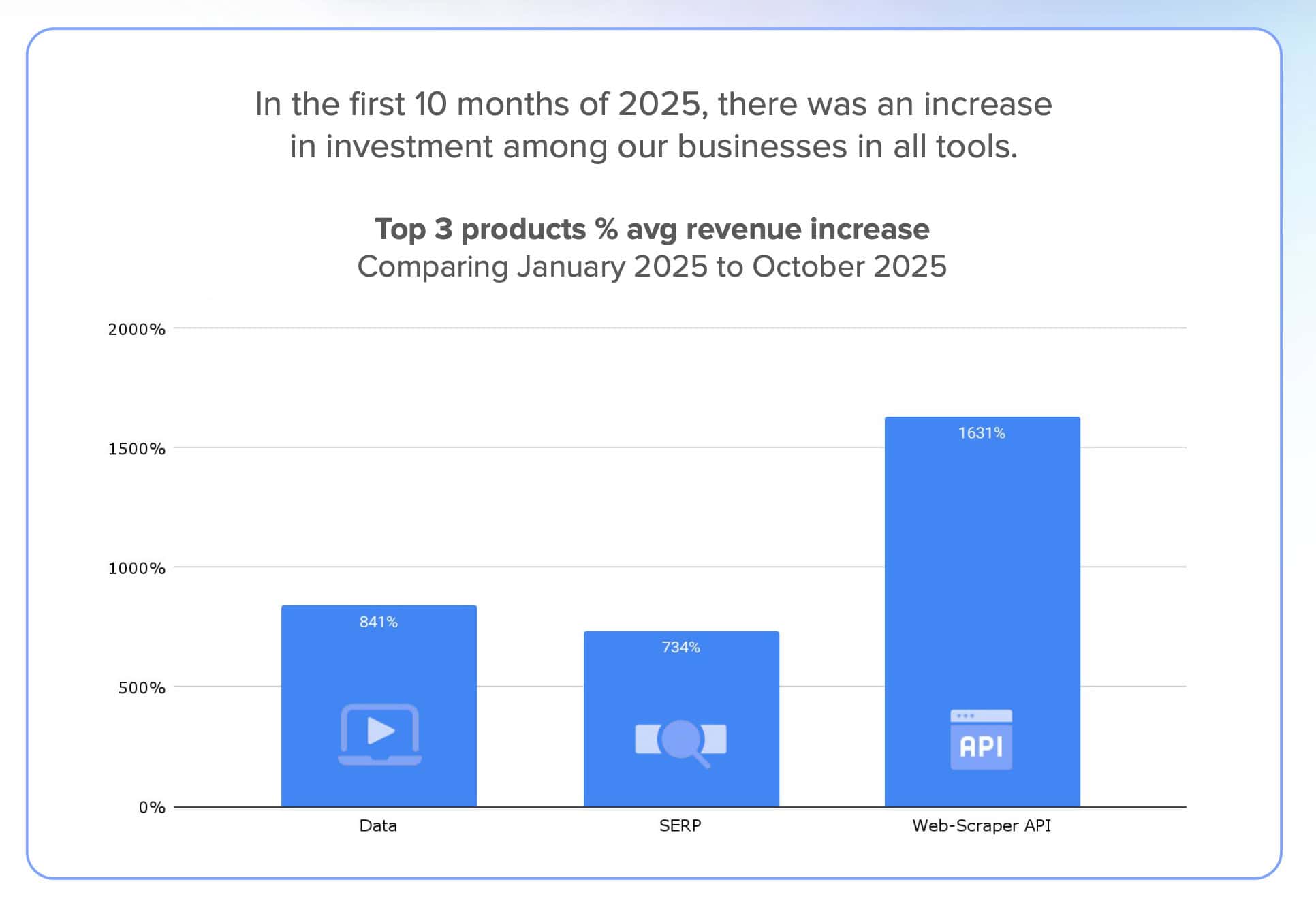
There are two important keywords in the lawsuit: deadweight loss, which really means ignored our ads, and the scale of scraping: based on Google’s data, SerpApi increased the number of requests by 25,000% over two years. Bright Data’s revenue data, which shows over 700% increase for its SERP API, corroborates this pattern.
While SerpApi and Google are fighting it out in the court, the legal teams of other providers watch closely, while their engineers shovel coal into the web scraping engine as fast as they can. Such is the price of opportunity.
Three Kinds of Google Scrapers
We’ve established that the market has splintered into three kinds of search engine scrapers: full, fast, and index-based. How do they compare? We’ve made a table to showcase their main features and strengths.
In brief, each chooses different trade-offs in the triangle of accuracy, speed, and completeness. If we compare two directly competing options, fast APIs and indices:
- Fast APIs give complete and fresh access to the SERP but not the pages it contains, requiring additional web scraping tools.
- Indices surface relevant pages and retrieve their contents very quickly, but the corpus of data risks being stale or incomplete.
| Full APIs | Fast APIs | Indices | |
| Output | All SERP elements, local search, ads | Crucial SERP elements (organic search, news) | Listed + extracted relevant pages |
| Retrieval | Real-time or very recent | Real-time or very recent | Index first, real-time as a fallback |
| Representation of the SERP | Faithful | Faithful | Unfaithful |
| Primary user | Human | AI, then human | AI |
| Use cases | Marketing agencies, SEO tools | Real-time data needs, RAG, deep research | RAG, deep research, AI agents |
| Strengths | Full SERP coverage, fresh output | Very fast, inexpensive, fresh output | Fastest, pre-processed output for AI |
| Weaknesses | Slow, limited suitability for AI | Limited SERP coverage, needs other tools for search & extract functionality | Limited SERP coverage, potentially stale data, expensive |
Landscape of Web Search APIs
Demand for search engine APIs is booming, and the market reflects that in the number of competitors. While we couldn’t list every one of them (most notably, the list misses Firecrawl and Parallel), we bought and benchmarked 15 services covering all three scraper types. Many were founded within the last few years.
| Full API | Fast API | Index | |
| Brave | ❌ | ❌ | ✅ |
| Bright Data | ✅ | ✅ | ❌ |
| DataForSEO | ✅ | ❌ | ❌ |
| Exa | ❌ | ❌ | ✅ (+live retrieval) |
| Jina | ❌ | ❌ | ✅ (+live retrieval) |
| LinkUp | ❌ | ❌ | ✅ |
| Oxylabs | ✅ | ✅ | ❌ |
| Perplexity | ❌ | ❌ | ✅ |
| ScrapingBee | ✅ | ✅ | ❌ |
| Scrapingdog | ✅ | ✅ | ❌ |
| SearchApi | ✅ | ✅ | ❌ |
| SerpApi | ✅ | ✅ | ❌ |
| Serper | ❌ | ✅ | ❌ |
| Tavily | ❌ | ❌ | ✅ (+live retrieval) |
| You | ❌ | ❌ | ✅ (+live retrieval) |
Search API Speed Test
AI use cases put a big premium on speed, especially when they function in latency-sensitive formats like audio conversations. Another important criterion is data relevance; but, as we’ll be comparing both direct and indirect representations of the search page, we have no good way to evaluate it.
To benchmark the search APIs for speed, we ran three tests on different days in mid-January (with the exception of Exa – Instant, launched in mid-February), each involving 2,000 requests at the rate of one per second.
We made randomly-generated queries, such as how tall are dogs. With indices, we chose their fastest mode where possible, which may impact result quality in production scenarios. Our server was located in the East Coast US.
At this scale, success rate was generally not a concern, so we omitted this metric. A word of caution for those with larger needs: scraping Google in real time is way less stable than it used to be.
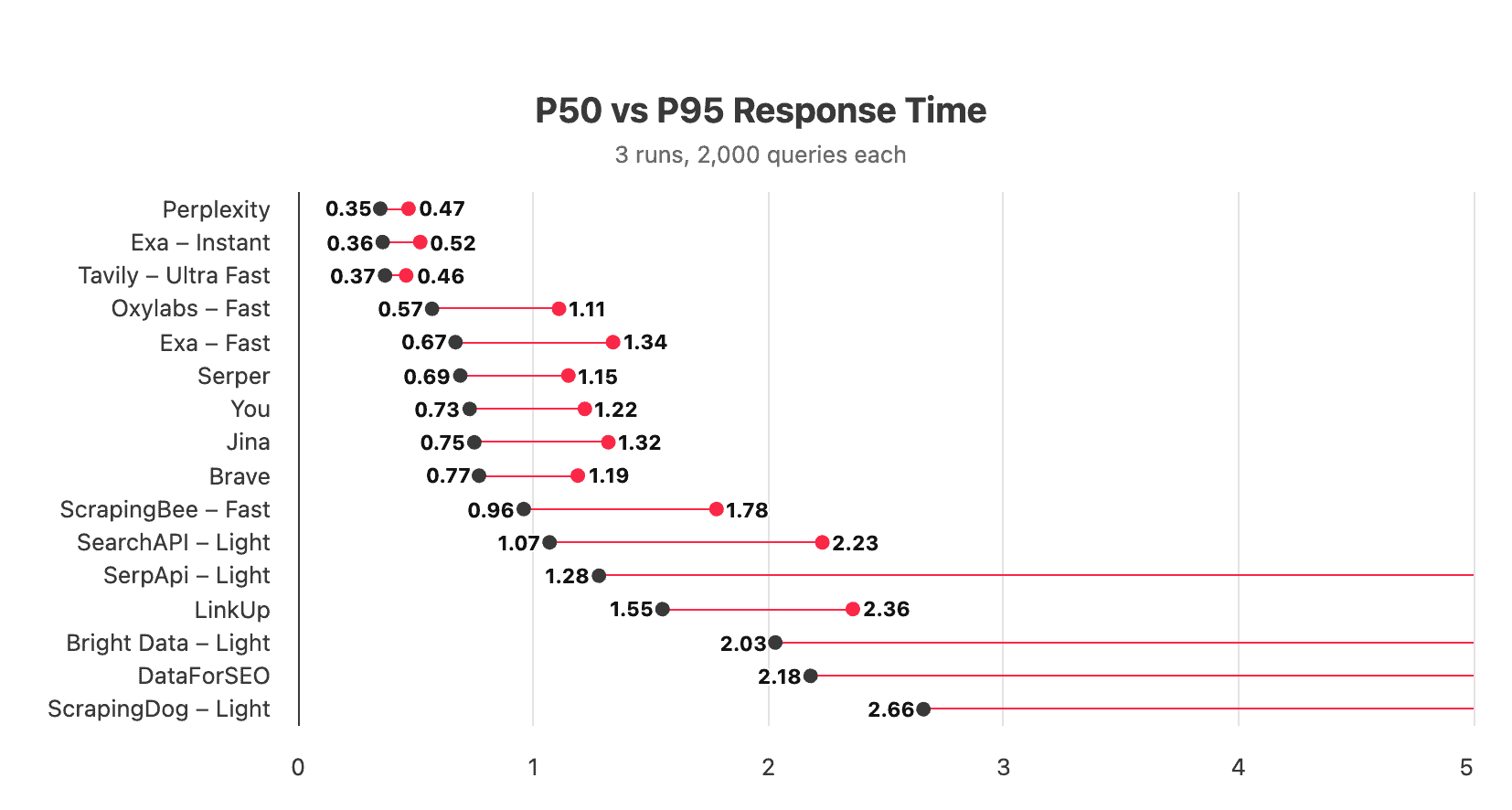
As expected, most index-type APIs were extremely fast. Perplexity, Exa, and Tavily all had effectively identical P50 response times, while You and Jina returned data around twice slower. Another distinguishing feature of indices was the small variance between the median and P95th result.
According to Exa, any search API that wraps Google has a minimum 700 ms P50. At our scale, we found this to be untrue: Oxylabs returned the SERP page nearly 20% faster, while Serper hovered around the 700 ms mark. Compared to indices, live APIs had a much bigger spread in latency. In four cases, the P95 response time exceeded five seconds.
Calculating the Costs
The differences between search API types make them surprisingly hard to compare. A closer investigation reveals several tendencies:
- Indices tend to rely on usage-based models: the low entry price makes them easy to pick up, but it also makes their public rates inflexible. The prices converge at around $5 per 1,000 results.
- The main price modifier is the processing needed to return a response.
- Real-time APIs rely on subscription plans much more than indices, which means that they require more initial commitment but scale better.
- However, they also need to factor in website extraction costs. Harder targets can charge multiples of the base request price.
| Model | Starting CPM | $1,000 CPM | Modifiers | Trial results | |
|---|---|---|---|---|---|
| Brave | PAYG | $3 | $3 | Usage conditions | 2,000/mo |
| Bright Data | PAYG, sub | $1.5 (+$1.5 for extraction) | $1.1 (+$1.1 for extraction) | Premium domains (x2) | 1,000 |
| DataForSEO | PAYG | $0.6 | $0.6 | Faster queue, live (x2, x3.3) | 1,000 |
| Exa | PAYG | $5 | $5 | Search depth (x3) | 670-2,000 |
| LinkUp | PAYG | $5 | $5 | Search depth (x10) | 100-1,000 |
| Oxylabs (Regular API) | Sub | $1 (+$1.15 for extraction) | $0.6 (+$0.75 for extraction) | JS rendering (x1.35) | 2,000 |
| Perplexity | PAYG | $5 | $5 | ❌ | ¯\_(ツ)_/¯ |
| ScrapingBee | Sub | $1.96 (+$0.2 for extraction) | $0.71 (+$0.07 for extraction) | API type (x2), extraction difficulty (up to x75) | 100 |
| Scrapingdog | Sub | $1 (+$0.2 for extraction) | $0.25 (+$0.05 for extraction) | API type (x2), extraction difficulty (up to x25) | 100-200 |
| SearchApi | Sub | $4 | $1.8 | Response speed (x2) | 100 |
| SerpApi | Sub | $25 | $7.25 | Response speed (x2, x4) | 250/mo |
| Serper | PAYG | $1 (+$1 for extraction) | $0.75 (+$0.75 for extraction) | ❌ | 2,500 |
| Tavily | PAYG, sub | $7.5 | Custom | Search depth (x2) | 62-125/mo |
| You | PAYG | $6.25 | $6.25 | # of results (x1.28) | 12.5-16k |
Let’s try graphing the price per 1,000 search & extract requests. This will better reflect the scaling – but be aware that we’re not taking into account any modifiers.

Real-time APIs nearly always come out cheaper. However, they require more work to achieve the same results as an index.
Conclusion
Thanks for reading our report! If you have any questions or comments, feel free to reach out through info at proxyway dot com or our Discord server.
