Easy Puppeteer Web Scraping Tutorial
This is a step-by-step guide to web scraping using the Node.js library Puppeteer.

Websites have changed a lot over the years. Web scraping modern sites or single-page applications requires rendering the entire page. They rely on elements like lazy loading and infinite scrolling, so traditional scripts aren’t of much help. A headless browser library such as Puppeteer plays a key role in web scraping dynamic websites.
In this step-by-step guide, you’ll find out why Puppeteer is such a popular Node.js library used in web scraping. You’ll also find a real-life example of how to scrape dynamic pages.
What Is Puppeteer Scraping?
Web scraping with Puppeteer is the process of controlling a headless Chrome browser to extract data from a target website. It’s a widely used Node.js library created by a team at Google in 2018. Even though Puppeteer is relatively new, the library is a popular choice for scraping JavaScript-dependent websites.
Puppeteer can automate most browser interactions like filling out forms, moving the mouse, waiting for the page to load, and taking screenshots, among other actions.
The library is maintained by Chrome Browser Automation developers, so you’ll have the most up-to-date browser version and functionalities. However, it properly supports only Chrome and Chromium; support for Firefox and Microsoft Edge is still in the experimental stage.
Advantages of Web Scraping with Puppeteer
Puppeteer is much faster than other headless browser libraries like Selenium. The main reason is that it uses Chromium’s built-in DevTools Protocol, which allows you to control the browser directly. It is also light on resources, so the execution time is relatively fast.
The library has great plugins like puppeteer-extra-plugin-stealth or puppeteer-extra-plugin-anonymize-ua that you can use to spoof your browser fingerprint. For example, you can rotate the headers or user agent. Besides, you can integrate proxies with Puppeteer.
Puppeteer is relatively easy to use. For example, it doesn’t have a built-in Integrated Development Environment (IDE) like Selenium for writing scripts, so you can use the IDE of your choice. For you, this means writing less code. What’s more, installing the library won’t take much time – add npm or yarn package managers and download the package.
Among all the functionalities, Puppeteer has well-crafted documentation and a large community of users. So, if you encounter any difficulties using the tool, finding the answer won’t take long.
Node.js and Puppeteer Web Scraping: A Step-by-Step Tutorial
Both links include dynamic elements. The difference? The second page is for dealing with delayed rendering. This is useful when a page takes time to load, or you need to wait before a specific condition is satisfied to extract the data.
Prerequisites
- Node.js. Make sure you have the latest Node.js version installed on your system. You can get it from the official website.
- Puppeteer. Since we’ll be using Puppeteer, you’ll also need to install it. Refer to the official website to learn how to install it on your system.
Importing the Libraries
Step 1. First, let’s import the necessary elements.
1) Import the Puppeteer library.
import puppeteer from 'puppeteer'
2) Since we’ll be using the built-in Node.js file system module, you’ll need to import it, too.
import fs from 'fs'
3) Then, import the URLs so you can scrape them.
const start_url = 'http://quotes.toscrape.com/js/'
//const start_url = 'http://quotes.toscrape.com/js-delayed/'
Setting Up CSS Selectors
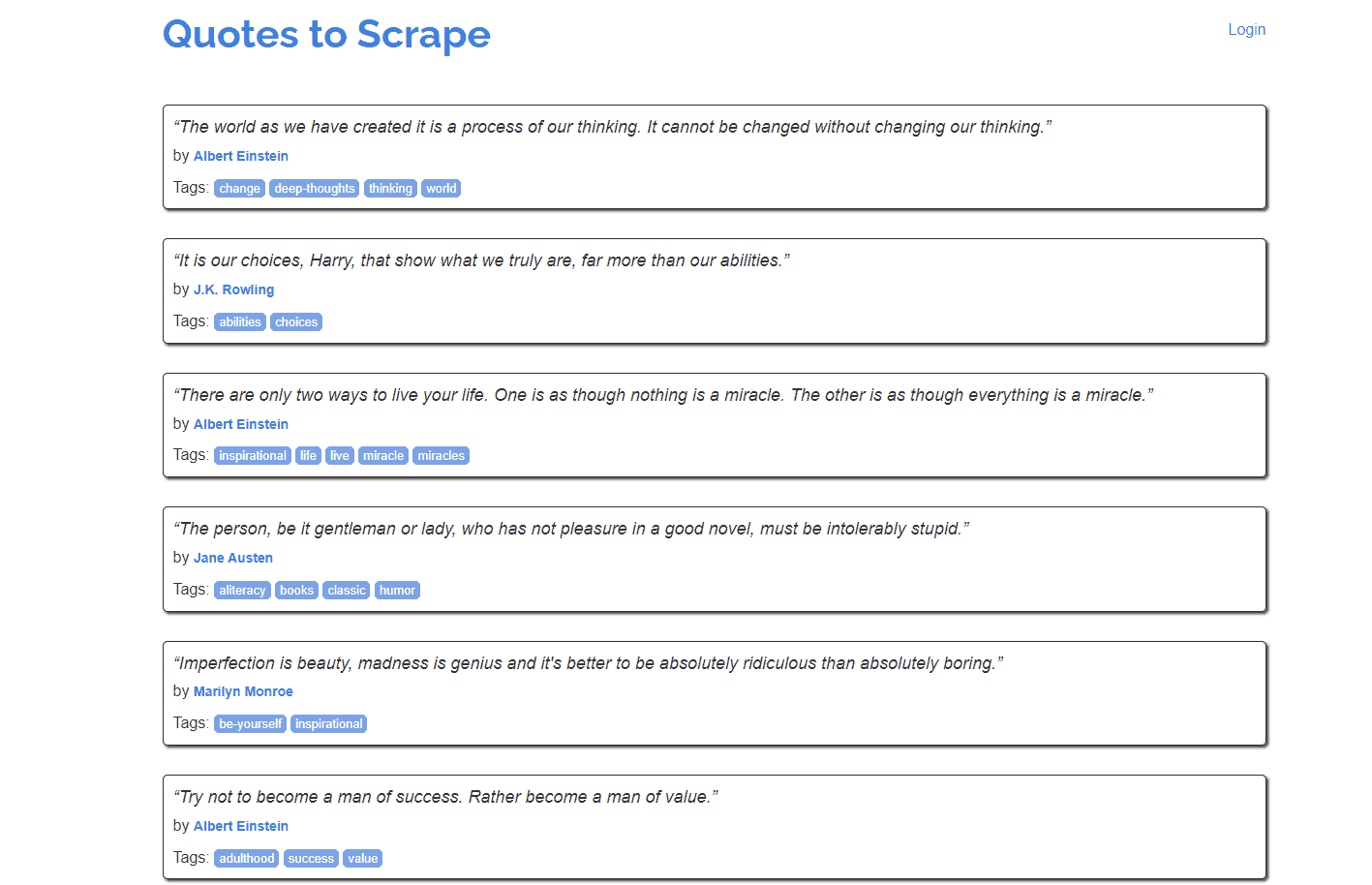
Step 1. Inspect the page source of quotes.toscrape.com/js by right-clicking anywhere on the page and pressing “Inspect”.

Step 2. You’ll need to select all the quote class objects and, within them, find the text for the following classes: text, quote, author, and tag.
const quote_elem_selector = '.quote'
const quote_text_selector = '.text'
const quote_author_selector = '.author'
const quote_tag_selector = '.tag'
const next_page_selector = '.next > a'
Step 3. Set up the list where you’ll write the scraped quotes.
var quotes_list = []
Preparing to Scrape
Step 1. We’ll use headful mode, so you can see what’s happening.
async function prepare_browser() {
const browser = await puppeteer.launch({
headless: false,
})
return browser
}
NOTE: If you want to add puppeteer-extra-plugin-stealth to hide your digital fingerprint or set up proxies to avoid IP-based restrictions, here’s the place to do so. If you don’t know how to set up proxies with Puppeteer, we prepared a step-by-step tutorial.
Learn how to set up a proxy server with Puppeteer.
Step 2. Then, write the main() function.
async function main() {
1) Call the setup_browser function to get the browser object.
var browser = await prepare_browser()
var page = await browser.newPage()
2) Now, let’s start to scrape with the start_url string.
await get_page(page, start_url)
3) Close the browser after the scraping is done.
await browser.close()
4) Print out the JSON output in the terminal window.
console.log(quotes_list)
}
5) When the code starts running, you’ll need to call the main() function.
main()
Scraping Multiple Pages with Node.js & Puppeteer
Step 1. Let’s use the get_page() function to go to the URL, get the HTML output, and move to the next page.
async function get_page(page, url) {
await page.goto(url)
1) Now, we’ll tell Puppeteer to wait for the content to appear using the quote_selector. Once an element with a class=quote appears, it will begin to scrape. We’ll set the timeout value to 20 seconds.
await page.waitForSelector(quote_elem_selector, {timeout: 20_000})
2) Then, call the scrape function to parse the HTML.
await scrape(page)
3) Check for a next page selector and extract the href attribute to scrape it.
try {
let next_href = await page.$eval(next_page_selector, el => el.getAttribute('href'))
let next_url = `https://quotes.toscrape.com${next_href}`
console.log(`Next URL to scrape: ${next_url}`)
4) Call the get_page() function again and pass the new_url to scrape.
await get_page(page, next_url)
} catch {
// Next page button not found, end job
return
}
}
Step 2. Now, let’s move to the parsing part. We’re going to use the scrape() function.
async function scrape(page) {
1) Find all quote elements and put them in the quote_elements list.
let quote_elements = await page.$$(quote_elem_selector)
2) Then, iterate through the list to find all the values for each quote.
for (let quote_element of quote_elements) {
3) Now, let’s find the elements we need using the selectors and extract their text content.
let quote_text = await quote_element.$eval(quote_text_selector, el => el.innerText)
let quote_author = await quote_element.$eval(quote_author_selector, el => el.innerText)
let quote_tags = await quote_element.$$eval(quote_tag_selector, els => els.map(el => el.textContent))
//console.log(quote_text)
//console.log(quote_author)
//console.log(quote_tags)
// Putting the output into a dictionary
var dict = {
'author': quote_author,
'text': quote_text,
'tags': quote_tags,
}
5) Push the dictionary into the quotes_list to get the output.
quotes_list.push(dict)
}
}
Here’s the output:
PS C:\node-projects\scraping> node .\index.js
Next URL to scrape: https://quotes.toscrape.com/js/page/2/
Next URL to scrape: https://quotes.toscrape.com/js/page/3/
Next URL to scrape: https://quotes.toscrape.com/js/page/4/
Next URL to scrape: https://quotes.toscrape.com/js/page/5/
Next URL to scrape: https://quotes.toscrape.com/js/page/6/
Next URL to scrape: https://quotes.toscrape.com/js/page/7/
Next URL to scrape: https://quotes.toscrape.com/js/page/8/
Next URL to scrape: https://quotes.toscrape.com/js/page/9/
Next URL to scrape: https://quotes.toscrape.com/js/page/10/
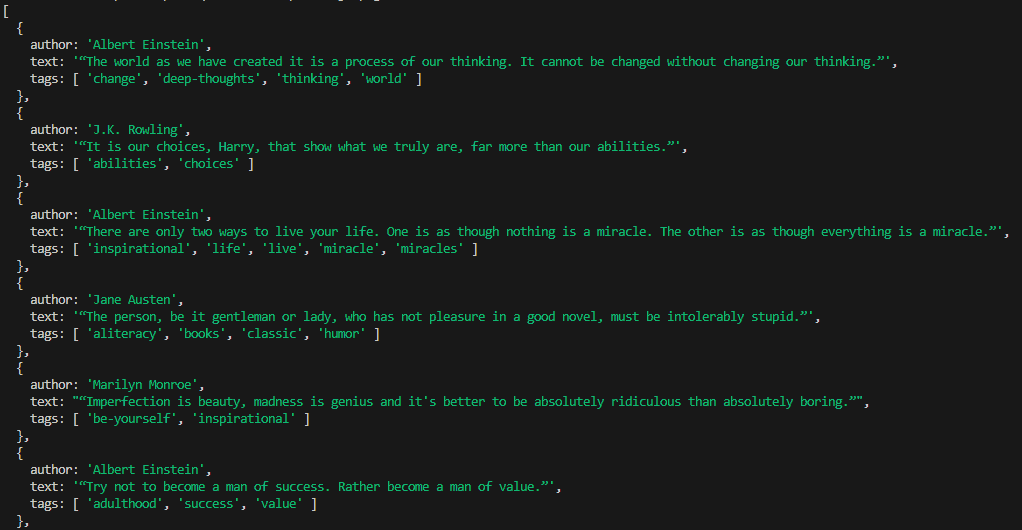
[
{
author: 'Albert Einstein',
text: '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”',
tags: [ 'change', 'deep-thoughts', 'thinking', 'world' ]
},
{
author: 'J.K. Rowling',
text: '“It is our choices, Harry, that show what we truly are, far more than our abilities.”',
tags: [ 'abilities', 'choices' ]
},
{
author: 'Albert Einstein',
text: '“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”',
tags: [ 'inspirational', 'life', 'live', 'miracle', 'miracles' ]
},
Saving the Output to a CSV File
Step 1. Create a function to write the output we’ve scraped and parsed to CSV:
function write_to_csv(){
1) Get the keys from the quotes_list object. This will be the first line of the csv file.
var csv = Object.keys(quotes_list[0]).join(', ') + '\n'
2) Iterate through each quote dictionary element.
quotes_list.forEach(function(quote) {
3) Add a new line to the CSV variable with the line break at the end.
csv += `${quote['author']}, ${quote['text']}, "${quote['tags']}"\n`
})
4) Write the output to the output.csv file
fs.writeFile('output.csv', csv, (err) => {
if (err)
console.log(err)
else {
console.log("Output written successfully")
}
})
}
Step 2. Write the main() function.
async function main() {
1) Initialize browser setup by calling the setup_browser function and get the browser object.
var browser = await prepare_browser()
var page = await browser.newPage()
2) Start to scrape.
await get_page(page, start_url)
3) Close the browser after the scraping is done.
await browser.close()
4) Print out the output json in the terminal window.
console.log(quotes_list)
5) Write the output to CSV.
write_to_csv()
}

Here’s the full code:
import puppeteer from 'puppeteer'
import fs from 'fs'
const start_url = 'http://quotes.toscrape.com/js/'
//const start_url = 'http://quotes.toscrape.com/js-delayed/'
const quote_elem_selector = '.quote'
const quote_text_selector = '.text'
const quote_author_selector = '.author'
const quote_tag_selector = '.tag'
const next_page_selector = '.next > a'
var quotes_list = []
async function prepare_browser() {
const browser = await puppeteer.launch({
headless: false,
})
return browser
}
async function get_page(page, url) {
await page.goto(url)
await page.waitForSelector(quote_elem_selector, {timeout: 20_000})
await scrape(page)
try {
let next_href = await page.$eval(next_page_selector, el => el.getAttribute('href'))
let next_url = `https://quotes.toscrape.com${next_href}`
console.log(`Next URL to scrape: ${next_url}`)
await get_page(page, next_url)
} catch {
return
}
}
async function scrape(page) {
let quote_elements = await page.$$(quote_elem_selector)
for (let quote_element of quote_elements) {
// Here we find the elements by using the selectors and extracting their text content
let quote_text = await quote_element.$eval(quote_text_selector, el => el.innerText)
let quote_author = await quote_element.$eval(quote_author_selector, el => el.innerText)
let quote_tags = await quote_element.$$eval(quote_tag_selector, els => els.map(el => el.textContent))
//console.log(quote_text)
//console.log(quote_author)
//console.log(quote_tags)
var dict = {
'author': quote_author,
'text': quote_text,
'tags': quote_tags,
}
quotes_list.push(dict)
}
}
function write_to_csv(){
var csv = Object.keys(quotes_list[0]).join(', ') + '\n'
quotes_list.forEach(function(quote) {
csv += `${quote['author']}, ${quote['text']}, "${quote['tags']}"\n`
})
//console.log(csv)
fs.writeFile('output.csv', csv, (err) => {
if (err)
console.log(err)
else {
console.log("Output written successfully")
}
})
}
async function main() {
var browser = await prepare_browser()
var page = await browser.newPage()
await get_page(page, start_url)
await browser.close()
console.log(quotes_list)
write_to_csv()
}
main()
